Еще раз о сложности¶
Нотация¶
$O, \Theta, \Omega$ - нотация
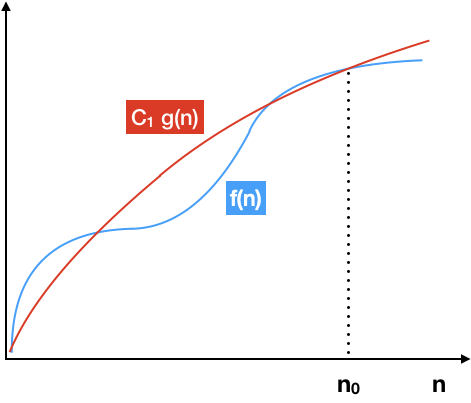
$O$ - нотация
Обычно в оценке сложности алгоритмов ограничиваются именно ей, так как $O(g(n))$ показывает, что функция $f(n)$, описывающая скорость роста алгоритма, растет не быстрее, чем заданная $g(n)$.
Отсюда "раcтут" линейный, квадратичный, $n \cdot log\ n$ и другие порядки роста
Математическая формулировка: существют такие $C_1$ и $n_0$, что $0 \leq |f(n)| \leq C_1 \cdot |g(n)| $ для всех $ n > n_0 $
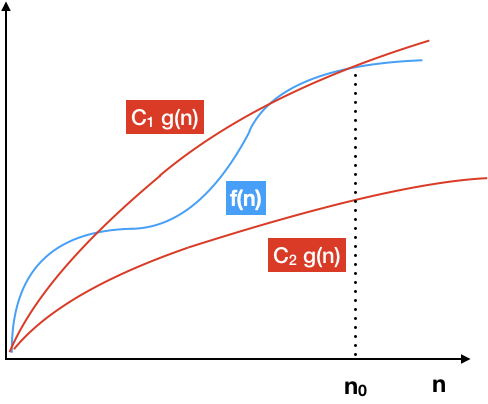
$\Theta$ - нотация
Это запись для ограничения роста функции сверху и снизу:
Существют такие константы $C_1$, $C_2$ и $n_0$, что $ 0 \leq C_1 \cdot |g(n)| \leq |f(n)| \leq C_2 \cdot |g(n)| $ для всех $ n > n_0 $
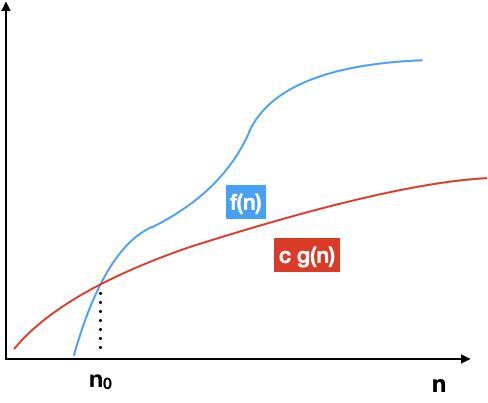
$\Omega$ - нотация
Ограничение скорости роста "снизу" (наверное, наиболее редкий вариант), может быть полезно при оценке адаптивных алгоритмов:
Есть такие константы $с$ и $n_0$, что $ 0 \leq с \cdot |g(n)| \leq |f(n)| $ для всех $ n > n_0 $
Итак, $O$ - это ограничение сверху, $\Theta$ - тот же порядок роста, $\Omega$ - ограничение снизу.
</font>
Минимально возможная сложность сортировки сравнением¶
Дерево решений
Имеется в виду не решающее дерево - алгоритм машинного обучения, но очень похожая структура.
Дерево является бинарным (т.е. из каждого узла выходят по две ветви). В узлах находятся проверки - сравнение двух элементов массива по определенным индексам.
При прохождении узла два элемента сравниваются, скажем, на то, какой из них больше. В зависимости от резултьтата проверки выбирается следующий узел.
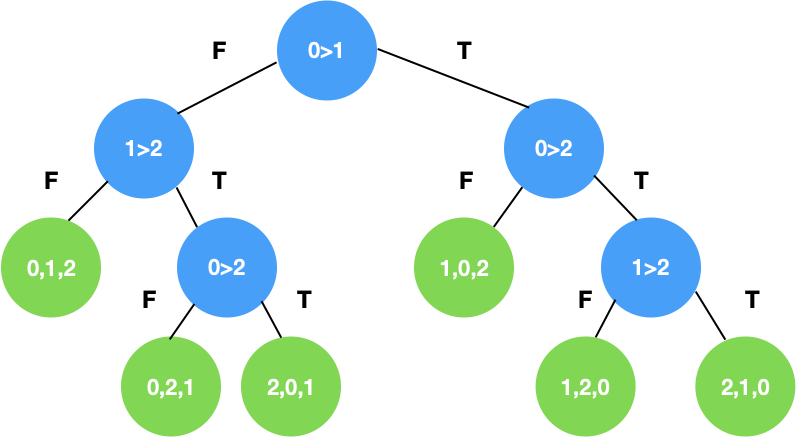
Для массива размером $n$ существует $n!$ перестановок. На исслюстрации изображены $3!$ перестановки для массива длиной 3 и пути, ведущие к ним: сравнение разных пар элементов массива.
Дойдя до листа, мы получаем информацию о порядке всех элементов, что необходимо для упорядочивания массива.
Поскольку алгоритм должен корректно обрабатывать все возможные перестановки, для оценки границы снизу $\Omega$ нам нужно ориентироваться на максимальную глубину дерева - максимальное количество сравнений.
$$ n! \leq 2^h,$$где $h$ - высота дерева
При этом, $h \geq log_2(n!) \geq \Omega (n \cdot log\ n))$. Доказательство последнего тождества можно посмотреть здесь (задача 3.2-3) либо попробовать самостоятельно доказать c помощью формулы Стирлинга.
</font>
Анализ MergeSort¶
Как оценить $O()$ для Merge Sort
Простой способ:
- посчитать стоимость операций Merge на каждом "уровне" дерева
- Посчитать глубину дерева, сложить стоимость Merge для всех уровней
Можно применить метод деревьев рекурсии
(да, деревья и рекурсия очень часто применяются при анализе алгоритмов)
- на верхнем уровне выполняется задача, допустим, за $f(n)$
- она разбивается на $k$ подзадач, выполняющихся за $f(n/d)$
- граничное условие выполняется за $T(1)$ - константное время
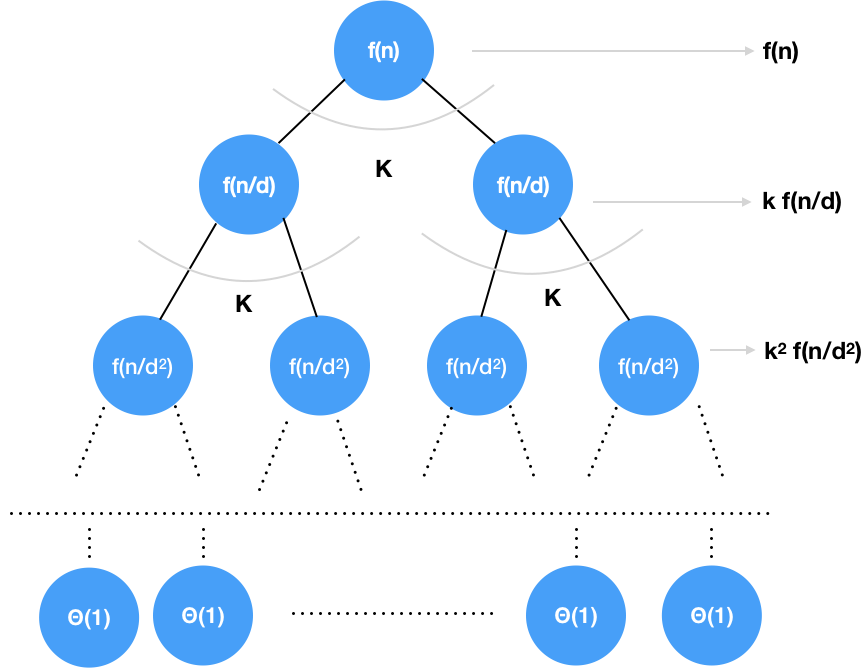
Количество операций, последний уровень - $\Theta(1) \cdot n^{log_d\ k} = \Theta(n^{log_d\ k})$
Общее количество операций в дереве описывается рекуррентным соотношением
Для вычисления сложности методом рекурсии применяются следующие выражения (в Кормене это называется "Основная теорема"):
Для констант $k, d$ и функции $f(n)$ для неотрицательных $n$ определено рекуррентное выражение
$$ T(n) = kT(n/d) + f(n),$$где $n/d$ округляется до целого.
Для $Т(n)$ верны следующие ассимптотические границы:
- Если $f(n) = O(n^{log_d k - \epsilon})$ для константы $\epsilon > 0$, то $T(n) = \Theta(n^{log_d k - \epsilon})$
- Если $f(n) = O(n^{log_d k})$ для константы $\epsilon > 0$, то $T(n) = \Theta(n^{log_d k} \cdot log\ n)$
- Если $f(n) = O(n^{log_d k + \epsilon})$ для константы $\epsilon > 0$, и $kf(n/d) \leq cf(n)$ для $c < 1$, то $T(n) = \Theta(f(n))$
- случай Merge Sort - второй, с константами $d = 2, k = 2$, то есть
$$f(n) = O(n^{log_2 2} \cdot log\ n) = O(n \cdot log\ n)$$</font>
Внешняя сортировка (External sorting)¶
В ситуациях, когда массив обрабатываемых (например, сортируемых) данных не помещается в (быструю) оперативную память, приходится привлекать внешние ресурсы (как правило, это жесткий диск; для многих задач они "неограничены")
External memory¶
Не физическое представление, а "математическая" модель.
Важно, что одним из критических мест в производительности становится процесс записи/чтения во внешнюю память.
Будем обозначать ограниченный объем оперативной памяти как $M$, и будем считать, что внешняя память разбита на неогрниченный набор блоков размера $B$.
Описание процесса сортировки¶
В начала сортировки массив $S$ хранится во внешней памяти, отсортированный массив записывается туда же.
- Считываем первые $N$ байт данных из внешней памяти, сортируем (напр., Quicksort), записываем во внешнюю память отсортированные данные
- Повторяем так $K$ раз ($K\cdot N \geq S$) - получаем $K$ отсортированных массивов во внешней памяти
- Merge!
- Возьмем из каждого массива $N / (K+1)$ байт c наибольшими значениями, и выделим еще столько же под выходной буфер.
- Делаем K-way merge
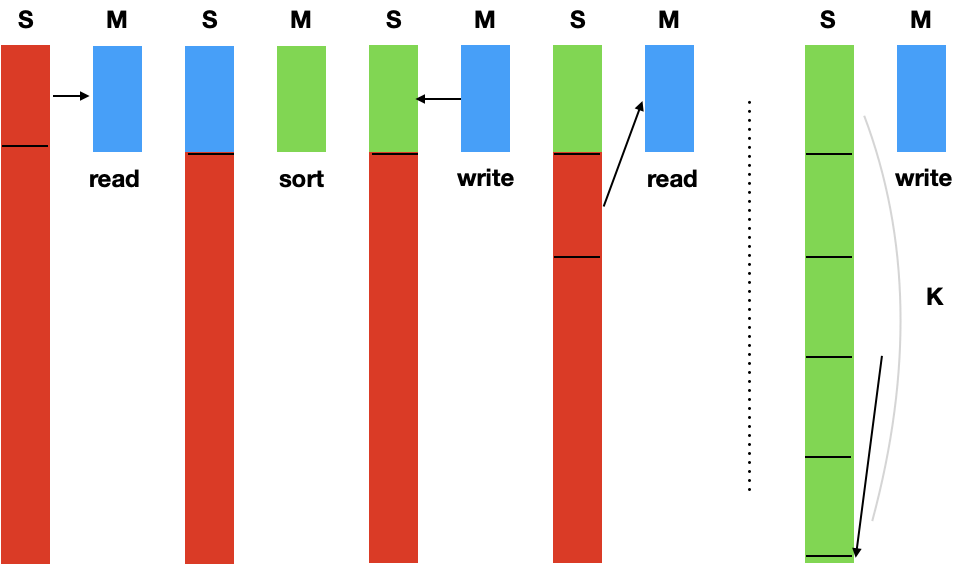
Вопрос: почему берутся первые $N / (K+1)$ байт?
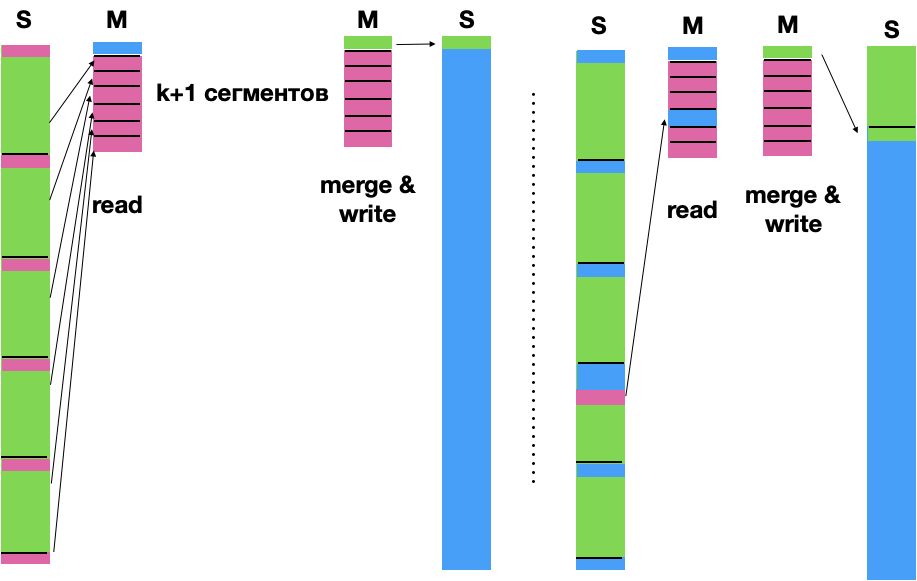

**will fix typos here**
K-way merge¶
K-way merge (без heap'ов)
Упрощенный вариант, не учитывающий то, что переодически массивы будут обновляться, а данные надо писать в буфер меньшего размера, чем сам массив
1 KWayMerge(Sorted, ArrayOfArrays, k): 2 Ptrs = новый массив из k указателей на k массивов, инициализирован 0 3 for i = 0 to length(Sorted): 4 index_of_array = FindMinArrayIndex(ArrayOfArrays, Ptrs) 5 Sorted[i] = ArrayOfArrays[index_of_array][Ptrs[index_of_array]] 6 Ptrs[index_of_array] += 1
FindMinArrayIndex возвращает индекс массива, в котором сейчас находится минимальный элемент. Ptrs модифицируется далее в коде, чтобы снизить риск сайд-эффектов.
Для упрощения туда не передается набор индексов-ограничений, чтобы случайно не выйти за пределы массива.
Сложность алгоритма $O(n \cdot k)$
K-way merge (с heap'ами)
Идея: сделать heap размера k, где ключами будут минимальные элементы каждого из списков, а ассоциированными с ними значениями - списки.
Напоминаю, как выглядит heap:
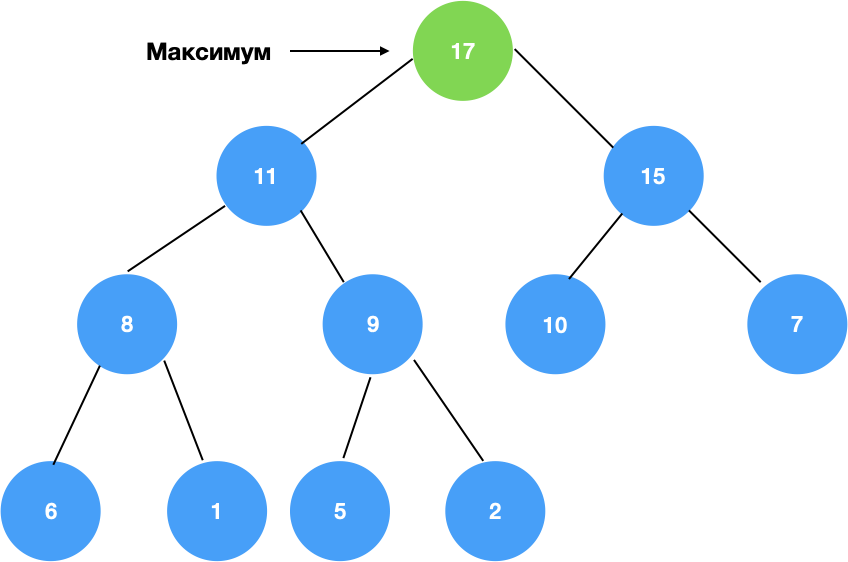
- только в нашем случае будет не max heap, a min heap
Сложность:
- BuildHeap за $O(k)$
- Минимальный элемент извлекается за $O(1)$, новый мимнимум в списке, из которого извлекли элемент - тоже
- За $O(log\ k)$ можно восстановить heap property
- Наконец, надо извлечь всего $n$ элементов, т.е. повторить перечисленные выше операции $n$ раз. Итого, сложность:
- это ощутимая экономия при больших значениях k
Наконец, K-way merge разделяй-и-властвуй
Предлагается использовать стратегию разделяй-и-властвуй для попарного слияния массивов из массива массивов в памяти.
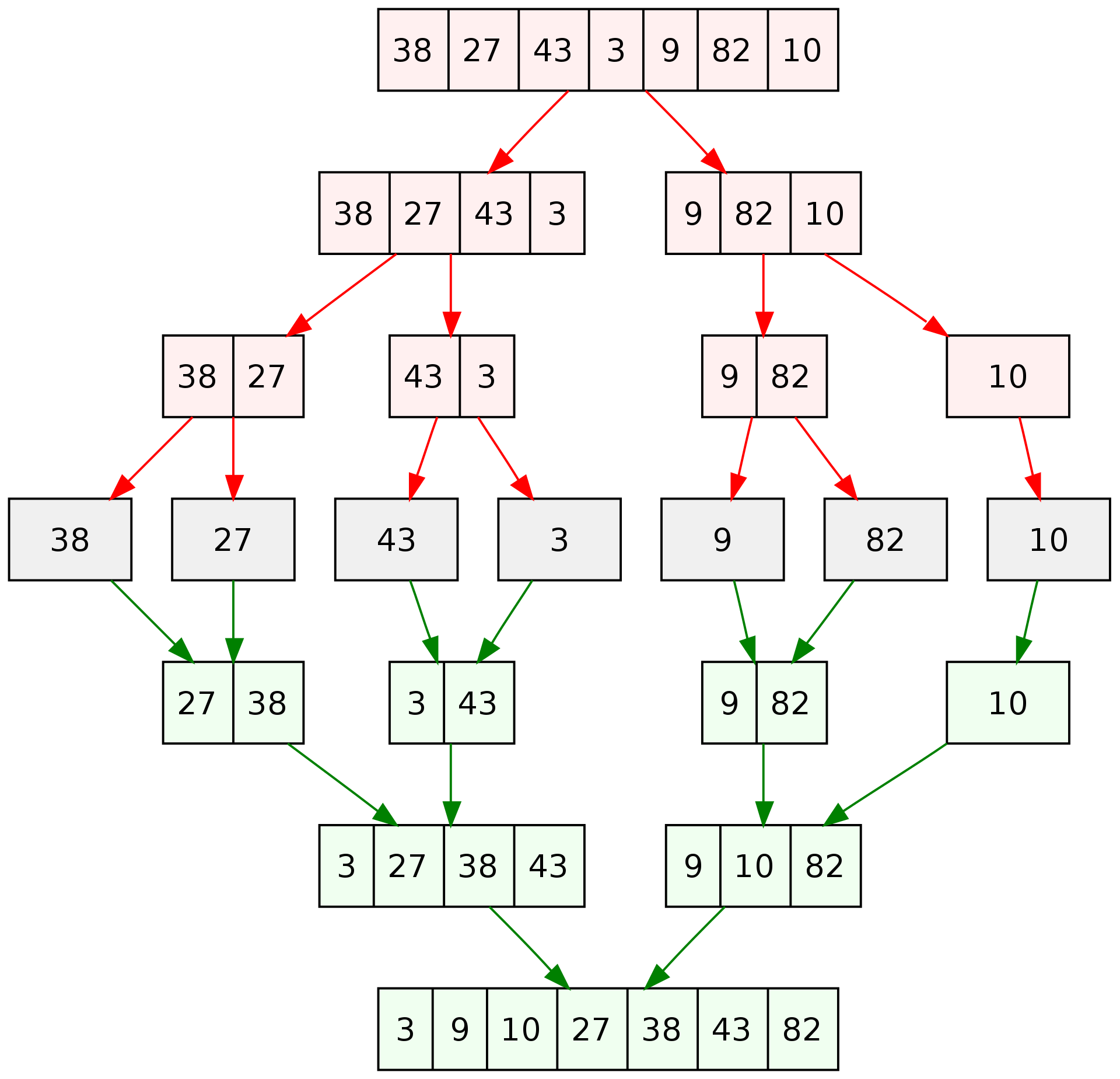
В теории, надо сделать $O(n \cdot log\ k)$ операций, сливая попарно массивы (практически полный аналог merge sort).
В чем отличия от heap-based K-way merge?
- Меньше сравнений - процедура восстановления свойсти кучи требует ~ $2 \cdot log\ k$ сравнений, а одна процедура слияния массивов (всех, на одном уровне) - ~ $n$ сравнений, и $log(k)$ уровней. В итоге получается ~ $2n \cdot log\ k$ у heap-based против $n \cdot log\ k$ у divide-and-conquer.
- Однако способ "разделяй-и властвуй" требует дополнительной памяти; в целом сравнение скорости требует экспериментальных проверок.
Псевдокод Merge:
1 Merge(Array, begin, middle, end, Copy): // ← Copy - это дополнительная память! 2 fst, snd = begin, middle 3 for ptr in range(begin, end) 4 if fst < middle and (snd >= end or Array[fst] <= Array[snd]) 5 Copy[ptr] = Array[fst] 6 fst += 1 7 else 8 Copy[ptr] = Array[snd] 9 snd += 1
</font>
Алгоритм поиска заданного элемента¶
Описание алгоритма
Функция Select(Array, i): Данный алгоритм использует метод "разделяй-и-властвуй".
- Разделение: оригинальный массив делится на $\lceil n/5 \rceil$ частей
- Для каждого подмассива находится медиана; они объединяются в массив медиан
- В массиве медиан рекурсивно при помощи
Selectищется медиана медиан, далее $x$ - Применяется Partition (как в Quicksort) для разделения массива на две части - меньше либо равных $x$, и больших элементов.
- Получим $k$ "меньших" элементов, и $(n-k)$ "больших".
- Если $k = i$, то возвращаем $x$ как целевой элемент.
- Иначе, ищем либо $i$-й среди меньшей части, либо, если $i > k$, $(i - k)$-й - среди большей
Как это выглядит

- в $k$ элементов входит и сам $x$
</font>
$k = 3 \cdot \lceil(n/5)/2\rceil$
$n - k$
$T(n) = T(\lceil n / 5 \rceil) + T(3 \cdot \lceil(n/5)/2\rceil)\ or \ T(\lceil n / 5 \rceil) + T(n - 3 \cdot \lceil(n/5)/2\rceil)$
Домашняя работа¶
- Основное: реализовать Select: 3 балла максимум; 2 балла - если есть недочеты, влияющие на производительность, но элемент выбирается за $O(n)$
- Дополнительное:
- реализовать сортировку, использующую (возможно, искуственные - я понимаю, что она сортировка будет работать долго, и тестировать будет непросто, если сортировать несколько Gb) ограничения по памяти, любым из алгоритмов k-way merge (2 балла).
- Сравнить работоспособность сортировки для разного количества блоков во внешней памяти - 10, 20, 50, 100.. или другая подобная последовательность (1 балл)
</font>