Формальное определение «O», «Θ», «Ω» большого.
Пришло время дать более строгие определения понятий, связанных с оценкой алгоритмической сложности. Не пугайтесь формул, по сути они передают то, о чём шла речь в прошлом уроке.
На математическом языке фраза «сложность алгоритма — » означает, что с увеличением параметра (то есть количества данных на входе) время работы алгоритма будет возрастать не быстрее, чем некоторая константа , умноженная на . То есть, начиная с какого-то функция расположена ниже, чем график функции для некоторого .
Нужно понимать, что для небольших значений это может быть совсем не так.

Важно, как алгоритм будет работать на больших объемах данных. Другими словами, как будет вести себя функция при очень больших значениях параметра . При оценке O-большого часто используется понятие асимптотической сложности. Так называется вычислительная сложность алгоритма при , стремящимся к бесконечности.
Более формально:

На самом деле — это класс функций, ограниченный сверху функцией ). Вернее было бы написать . Знак равенства используют скорее для удобства. Это не равенство в привычном смысле, а несимметричное отношение. Мы не можем прочитать это равенство в обратную сторону.

Обратите внимание, мы как будто отбросили слагаемые и .
Чтобы разобраться, почему так можно делать, посмотрим на график:
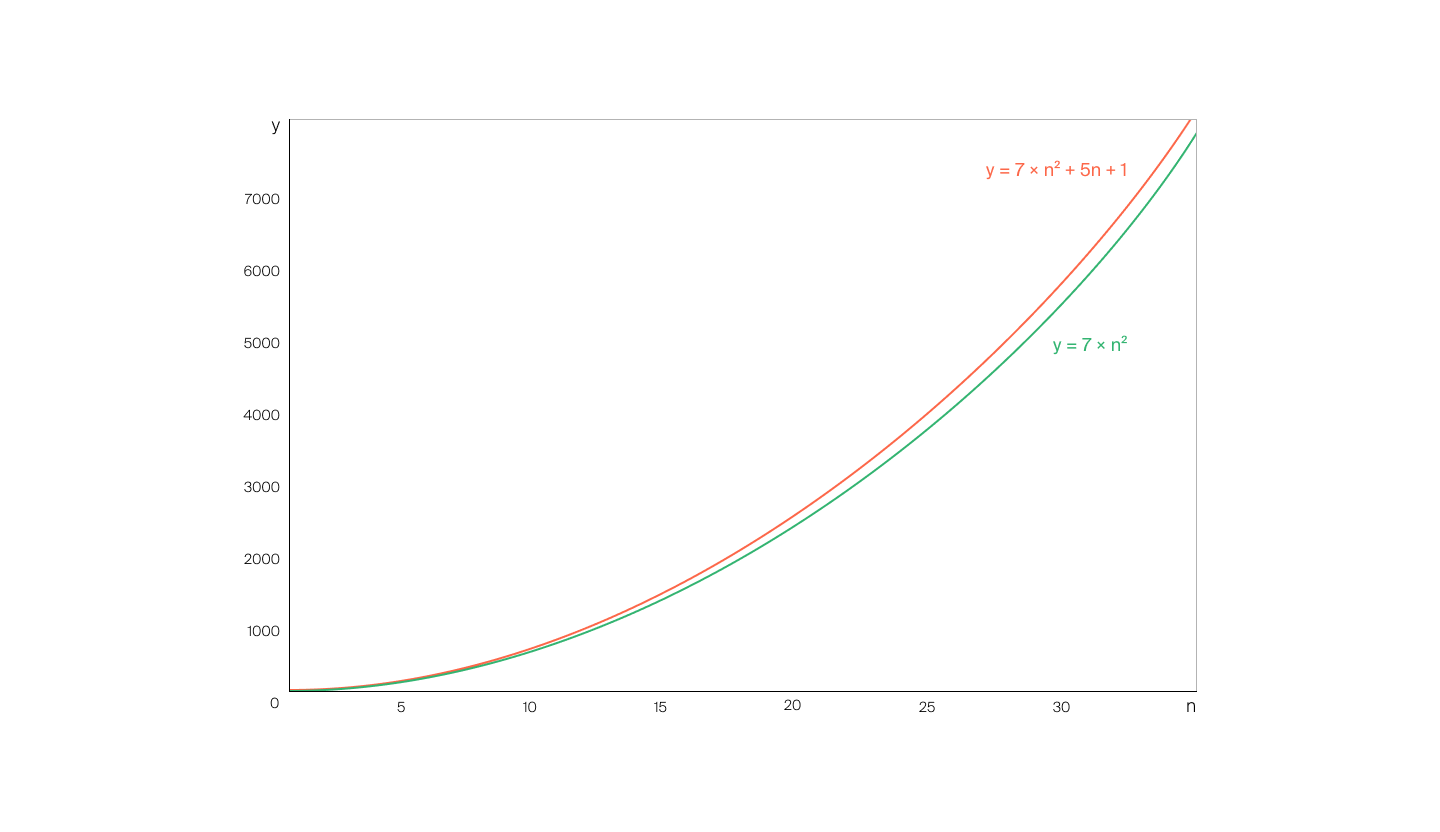
Видно, что функции и c увеличением ведут себя примерно одинаково.
То есть слагаемые и вносят несущественный вклад по сравнению с , особенно при больших . Эти слагаемые имеют меньшую скорость роста, чем . Формальное доказательство данного факта будет чуть позже в этом уроке. Поэтому их можно не принимать во внимание.
Также важно отметить, что мы не учитываем множитель при , когда пишем, что . Этот множитель часто называют коэффициентом амортизации. Сейчас разберёмся, почему его можно опустить.
Вы уже знаете, что при оценке вычислительной сложности не учитывают такие факторы как процессор, операционная система компьютера и язык программирования, на котором реализован алгоритм.
Допустим, процессор на одном компьютере в два раза быстрее, чем на втором. Алгоритм, реализованный на C++, может закончить работу в полтора раза быстрее, чем алгоритм, написанный на Python. Принимать это во внимание мы не хотим.
Поэтому константа игнорируется при определении .
Если вы, к примеру, обрабатываете массив, проходясь последовательно по всем его элементам, то для определения неважно, будет ли на каждом шаге произведена одна, две или десять операций. Учитывают только переменные, зависящие от объёма входных данных.
Представьте отбор в команду волейболистов. В команде может быть произвольное количество игроков, но все они должны быть ростом не ниже пяти сантиметров по сравнению с самым высоким из них. Эту задачу можно решить за два прохода. Сначала определить рост самого высокого человека, затем — выбирать игроков, сравнивая рост каждого с найденным на первом шаге максимумом. Будет сделано два шага, но все равно сложность останется .
Если нужно отобрать пять самых высоких игроков, можно отсортировать их по росту. Пятеро первых и будут самыми высокими. Воспользуемся алгоритмом «сортировка выбором»: на каждом шаге выбираем наименьший элемент в массиве и меняем его местами с элементом на позиции . Реализацию (код) алгоритма сейчас рассматривать не будем — сортировкам посвящён отдельный урок. А пока посмотрите, как он работает:
Сколько операций потребуется для алгоритма «сортировка выбором»? На каждой итерации , где принимает значение от до , сравниваем элемент на -ой позиции раз. Получим, что сложность будет .
Теперь представьте, что каждый раз при сравнении вы записываете данные, чтобы потом проверить свои действия. Операций потребуется в два раза больше, ведь вы ещё запоминаете результат каждой операции сравнения. Но два — это константа, а константы не влияют на асимптотику, то есть всё равно сложность алгоритма будет .
Теперь интуитивно понятно, почему при оценке мы опускаем некоторые слагаемые. Давайте покажем это строго:

Получаем, что функции и при больших отличаются на константу. То есть можно взять такую константу, что график функции начиная с какого-то будет лежать ниже графика функции умноженную на эту константу. По определению получаем, что .
Выражение означает, что функция . ограничена сверху функцией , умноженной на некоторую константу.
Корректно будет сказать, что, например:

Но при анализе сложности алгоритмов мы хотим найти наиболее точную оценку. То есть нужно определить функцию, ограничивающую нашу функцию сверху, но как можно более близкую к ней.
Выражение и говорит о следующем. Если при больших алгоритм работает примерно секунду, то при удвоении объёма данных время работы возрастет в четыре раза.
Помимо существуют другие оценки сложности алгоритмов: ( произносится «тета») и ( произносится «омега»).

На графиках показан смысл этих трёх показателей:
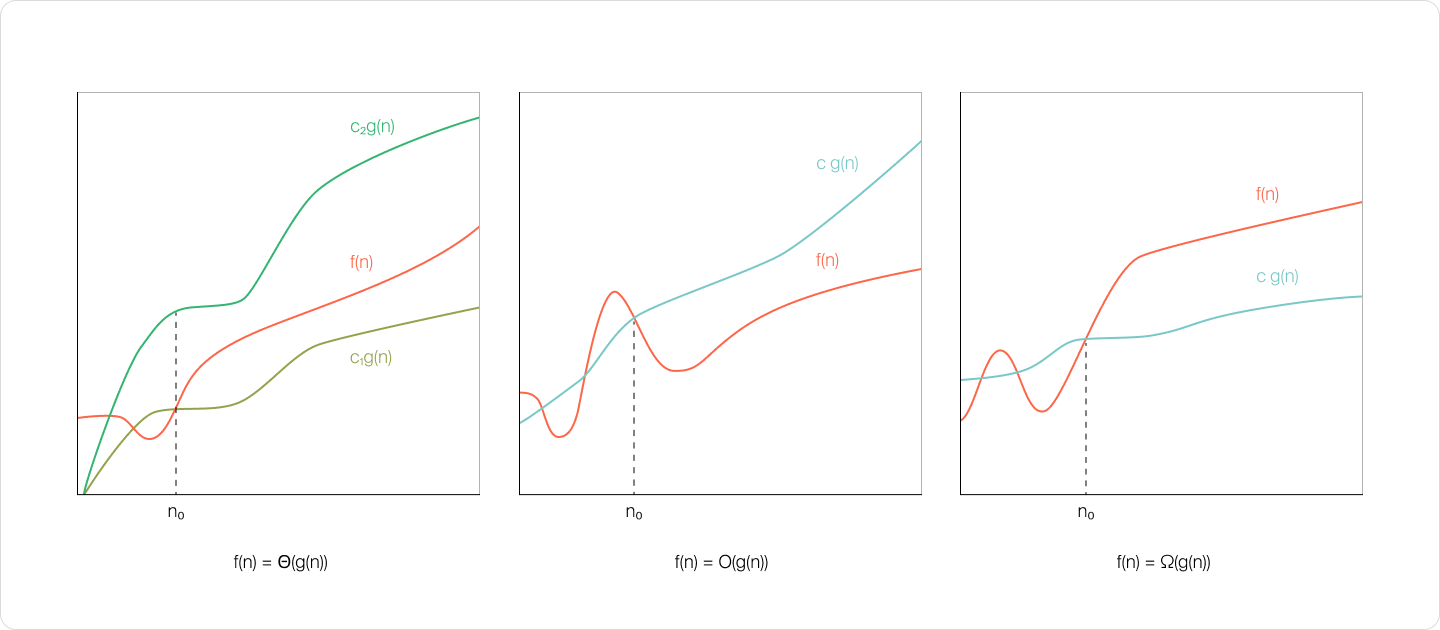
Однако на практике чаще всего используют . Эту характеристику обычно проще посчитать, и она более полезна.
Подведём итог. Вы познакомились с O-символикой (так по-другому называют О - нотацию).
Плюсы метода:
- Помогает определить зависимость времени работы алгоритма от объёма входных данных.
- Позволяет сравнивать алгоритмы между собой.
- Упрощает анализ сложности. Нам не нужно задумываться о том, сколько на самом деле занимает каждая операция.
- Сложность алгоритма не зависит от машины, на которой запускается программа, языка программирования и других факторов, учитывать которые мы не хотим.
- Даёт более простые оценки сложности: вместо .
Но, как и у многих методов, у данного подхода есть недостатки.
При его использовании не учитываются константы и слагаемые, имеющие меньшую скорость роста.
На практике есть разница, будет алгоритм работать за или, к примеру, за . Константы имеют значение. Будет ли ваша программа работать 10 или 100 секунд, будут ли в функции слагаемые, имеющие меньшую скорость роста и поэтому отброшенные при анализе, — все это играет роль. Если вы хотите писать эффективный код, следует обращать внимание не только на асимптотическую сложность.
Допустим, для решения задачи есть два алгоритма с одинаковой асимптотической сложностью . Но функция временной сложности первого имеет вид , а второго — , то стоит выбрать первый.
Есть определённые правила оценки эффективности алгоритмов с применением «O» большого. О них вы узнаете в следующем уроке.