Введение. Примеры использования различных структур данных
В этом уроке вы узнаете про некоторые базовые структуры данных, применяемые в программировании для хранения информации.
Структурой данных называется программная единица, которая позволяет хранить и обрабатывать множество однотипных или логически связанных данных.
В большинстве языков программирования есть ограничение — в структуре данных можно хранить только элементы фиксированного типа. Но, например, в Python или JavaScript такого требования нет.
В школе у Аллы была та же классная руководительница, что у её брата Васи сейчас. Иногда учитель обращается к Алле за помощью. В этот раз классная руководительница хочет собрать статистику посещаемости дополнительных кружков. Вася учится в частной школе, где в каждом классе не более десяти учеников. В его классе восемь человек. Нужно где-то хранить их имена и фамилии. Какая структура данных подойдёт для этой задачи?
Рассмотрим массив. Эта структура данных хранит набор значений, к которым можно обращаться по индексу.
Эта операция выполняется за О(1). Если первый элемент в массиве имеет индекс 0, то адрес конкретной ячейки, в которой лежит элемент вычисляют по формуле:
AddressOfElementN = AddressOfArray + (N * sizeof(ElementType))
Но не во всех языках программирования индексация в массиве начинается с нуля. Например, в Lua или Pascal индекс первого элемента — 1.
В таком случае формула определения адреса элемента примет вид:
AddressOfElementN = AddressOfArray + ((N - 1) * sizeof(ElementType))
Пример массива:
Скопировать кодPYTHONprogramming_lanquages = ["Python", "Java", "C++", "Ruby", "Scala"] Массивы бывают статические и динамические. Размер статического массива задаётся при создании и не изменяется. Динамический же массив может изменяться во время исполнения программы. В некоторых языках программирования доступна реализация обоих типов, как в С++. А в некоторых языках — только одного. Например, в Pascal есть только статические массивы.
Эту структуру данных легко представить в виде ряда. У каждого элемента ряда есть номер. По этому номеру можно получить значение элемента.
Скопировать кодPYTHONprogramming_lanquages[0] # "Python" Элементы массива расположены в последовательных ячейках памяти.
Массив удобно применять, когда нужно сохранить набор элементов в определённом порядке.
Длина массива равна количеству элементов, которые в нём хранятся.
Поэтому чтобы посчитать длину массива, нужно пройтись по всем элементам и посчитать их количество. В общем случае понадобится О(n) операций.
Но, к примеру, в языке Python можно определить длину массива за O(1). Это число хранится в структуре, привязанной к каждому объекту, у которого можно посчитать эту величину.
Итак, массив Алле отлично подходит. В каждом элементе массива может быть строка, содержащая фамилию и имя ученика:
Скопировать кодPYTHONpupils = ['Бутылкин Василий', 'Петров Борис', 'Чашкина Василиса', 'Зайцев Макар', 'Яблоков Геннадий', 'Заборчиков Михаил', 'Котовасин Роман', 'Забывакина Раиса'] Например, вот списки кружков Бутылкина Васи и Чашкиной Василисы:
Скопировать кодPYTHONvasya_butylkin_optional_courses = [
'вышивание крестиком',
'рисование мелками на парте',
'настольный керлинг',
]
vasilisa_chashkina_optional_courses = [
'настольный керлинг',
'кухня африканского племени ужасмай',
'тяжелая атлетика',
'таракановедение',
] Нужно определить, какие кружки посещает хотя бы один ученик в классе. Можно создать массив и поместить в него сначала кружки для первого ученика, затем для второго и продолжать, пока не переберём всех. Потом поискать в списке повторяющиеся элементы и удалить лишние вхождения.
Этот алгоритм можем записать так:
Скопировать кодPYTHONvisited_optional_courses = list()
for course in vasya_butylkin_optional_courses:
visited_optional_courses.append(course)
for course in vasilisa_chashkina_optional_courses:
visited_optional_courses.append(course)
... В примере рассматриваем двух учеников, Васю и Василису. Общий список их кружков:
Скопировать кодPYTHONvisited_optional_courses =
['вышивание крестиком',
'рисование мелками на парте',
'настольный керлинг',
'настольный керлинг',
'кухня африканского племени ужасмай',
'тяжелая атлетика',
'таракановедение']
Убираем дубликаты:
Скопировать кодPYTHONunique_courses = []
for course in visited_optional_courses:
if course not in unique_courses:
unique_courses.append(course) Получаем нужный результат. Но, кажется, были проделаны лишние действия.
Убедиться, что сложность алгоритма квадратичная, можно иначе. На первой итерации массив unique_courses пустой, значит, сравнения не будет: ноль операций сравнения и одна операция добавления в массив. На следующем шаге будет максимум две операции: сравнения и добавления в массив. На третьем шаге две операции сравнения и одна — добавления в массив.
Обратите внимание: если все элементы в массиве visited_optional_courses разные, это худший случай, ведь мы на каждой итерации добавляем элемент в массив. То есть производим максимально возможное количество сравнений. На шаге n мы в худшем случае проделаем n операций. Посчитаем их общее количество: 1 + 2 + 3 + ... + n.
Это арифметическая прогрессия. Её сумма может быть вычислена по формуле:
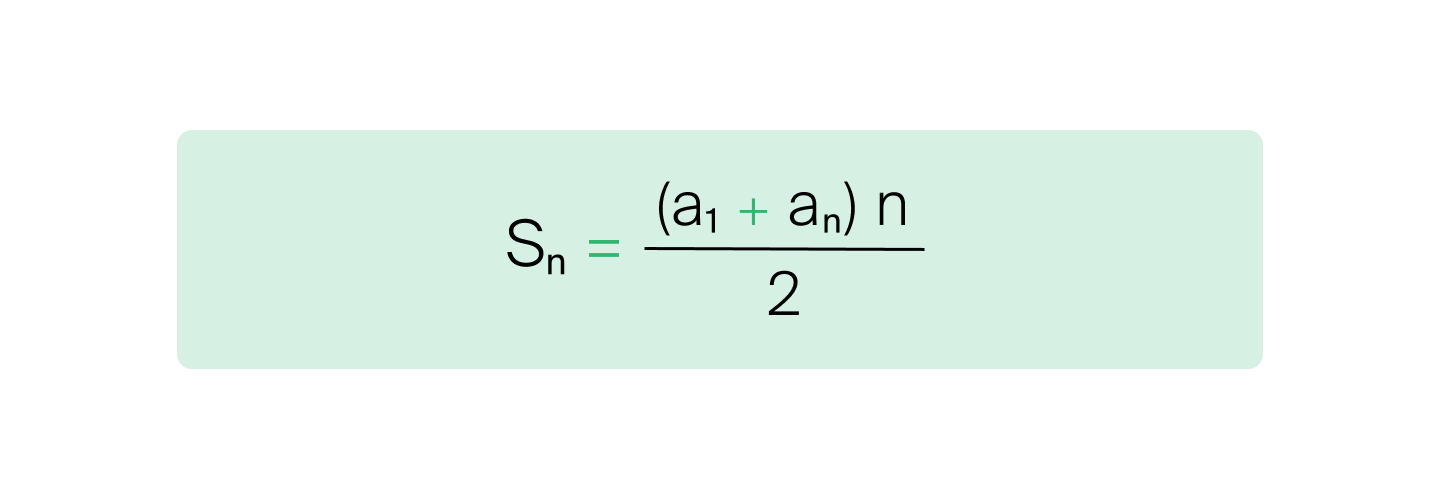
Подставив наши значения, получим S = (n² + n) / 2. Как видите, сложность алгоритма правда O(n²).
Решение можно улучшить. Дело в том, что применение массива — не лучший вариант для этой задачи. Нужно применить другую структуру данных. Рассмотрим множество.
Множество хранит уникальные элементы. В него можно добавить только тот элемент, который в нём ещё не содержится.
Последовательно проходим по списку кружков каждого ученика и пробуем добавить их во множество. В результате получим объекты, которые посещает хотя бы один ученик в классе. Именно это и нужно.
Скопировать кодPYTHONvisited_optional_courses = set()
for course in vasya_pupkin_optional_courses:
visited_optional_courses.add(course)
for course in vasilisa_chashkina_optional_courses:
visited_optional_courses.add(course) Посмотрим на примере.
Добавим во множество кружки Васи. После этого в нём будет три объекта.
Скопировать кодPYTHONvisited_optional_courses = {
'вышивание крестиком',
'рисование мелками на парте',
'настольный керлинг',
} Далее будем добавлять кружки Василисы. При попытке вставить настольный кёрлинг множество не поменяется. После того, как пройдём по всем элементам массива факультативов Василисы, в множестве станет шесть элементов.
Скопировать кодPYTHONvisited_optional_courses = {
'вышивание крестиком',
'рисование мелками на парте',
'настольный керлинг',
'кухня африканского племени ужасмай',
'тяжелая атлетика',
'таракановедение',
} Добавив кружки остальных, получим список занятий, которые посещает хоть кто-то из учеников.
Другой пример. В С++ множество реализовано с помощью иной структуры данных — бинарного дерева поиска или BST. Операции поиска и вставки в такое дерево выполняются за логарифмическое время. То есть общая сложность алгоритма O(nlogn).
Сложность добавления элемента и проверки на наличие элемента во множестве зависит от языка программирования и составляет О(1) либо O(logn). В случае со списком сложность этих операций будет О(n). То есть когда для решения задачи подходит и массив, и множество, алгоритм со множеством в общем случае работает эффективней.
Если вы не до конца понимаете, почему сложность операций при работе с множествами и хеш - таблицами именно такая, — ничего страшного. Это непростая тема. В этом уроке мы только рассмотрели примеры, в которых удобно применять разные структуры данных.
В следующих уроках вы разберётесь со сложностью операций при использовании множеств, массивов, связных списков и других структур данных.
А теперь - решите задачи A и B из контеста.