Коллизии. Метод цепочек
Алла: А часто вообще коллизии возникают на практике?
Тимофей: Чтобы ответить на этот вопрос, рассмотрим пример. Вы слышали про парадокс дней рождений?
Алла: Нет, расскажи, пожалуйста.
Вычислим вероятность, что все дни рождения будут в разные даты. Для этого посчитаем произведение вероятностей того, что день рождение каждого человека не совпадёт ни с чьим другим.
Для первого человека такая вероятность будет равна 1. Для второго человека — , так как один день уже занят. Для второго занято будет уже 2 дня. И так далее.
.
Нас интересует событие, обратное этому.
Посмотрим на график зависимости вероятности минимум двух совпадений от количества людей:

Если взять 23 человека, вероятность будет 50%.
Значит, что если взять таблицу, в которой 365 значений, и расположить в ней 23 ключа, то уже в этом случае вероятность коллизии будет 50%.
Построить хеш-таблицу, в которой никогда не будет коллизий, — сложно, поэтому нужно уметь бороться с ними.

Коллизия — это ситуация, когда для разных данных функция возвращает одно и то же значение.
Гоша: А что же делать в таком случае?
Тимофей: Существуют разные способы решения этой проблемы. Например, метод цепочек.
Вам хорошо знакома такая структура данных как связный список. Её используют в методе цепочек при разрешении коллизий.
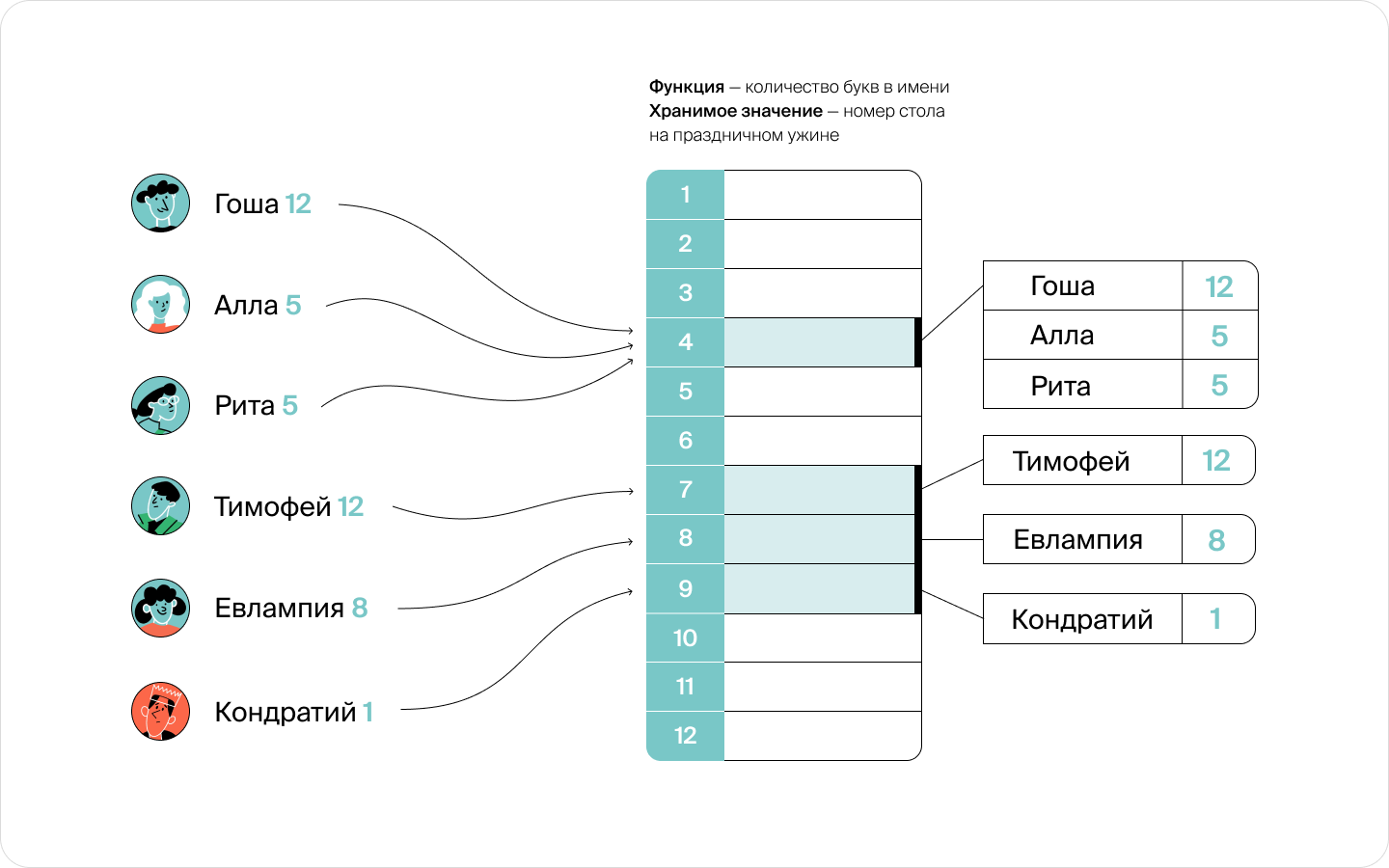
Допустим, нужно добавить ключ:
- Вычисляем значение хеш-функции от добавляемого ключа.
- Находим — указатель на список ключей.
- Вставляем элемент в связный список.
При удалении ключа нужно:
- Вычислить значение хеш-функции от ключа.
- Найти — указатель на список ключей.
- Выполнить поиск ключа в связном списке и удалить его.
Гоша: А какое среднее время работы всех операций?
Тимофей: Среднее время работы операции удаления, поиска и вставки в хеш-таблицу, реализованную с использованием метода цепочек, равно , где — коэффициент заполненности таблицы (англ. fill factor).
, где — количество элементов в таблице, а — размер таблицы.
Гоша: А почему именно ?
Тимофей: Найдём ожидаемое время работы в зависимости от исходного ключа.
Время обработки ключа зависит от длины цепочки и равно , где — длина i-й цепочки. Единица затратится на вычисление значения хеш-функции, — на поиск элемента в цепочке. Предполагаем, что хеш-функция равномерная, то есть все значения равновероятны. Тогда:
где — математическое ожидание времени работы в зависимости от ключа .
В каждую ячейку попадём с вероятностью .
.
Если попадаем в ячейку , то время работы — именно столько потребуется, чтобы пройти всю цепочку.
.
Единица суммируется раз, суммарная длина всех цепочек равна .
.
Среднее время можно регулировать. В зависимости от объёма данных, которые предполагается хранить в хеш-таблице, можно выбирать размер таблицы так, чтобы значение a не превышало определённый порог.