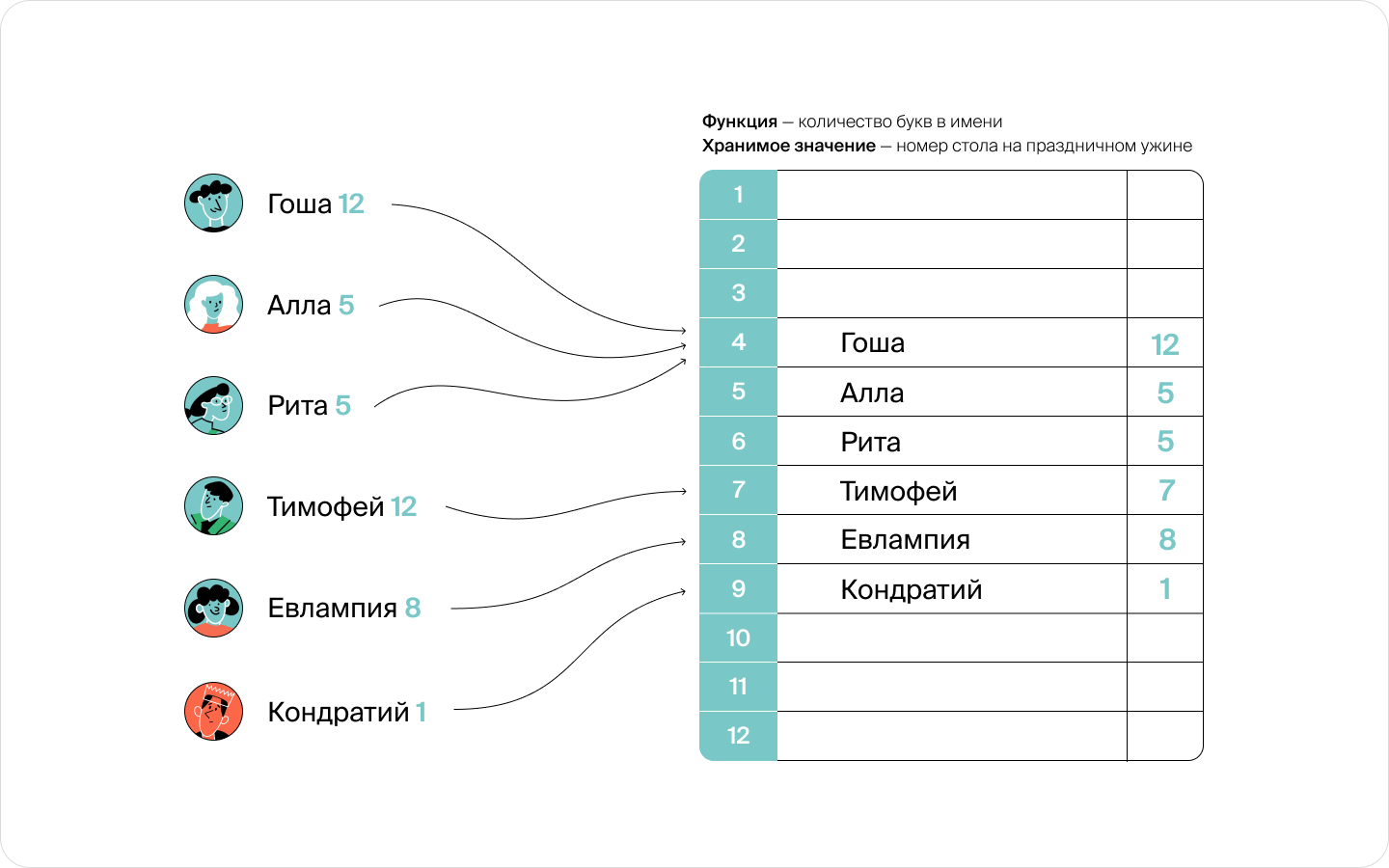
Метод открытой адресации
Тимофей: Другой способ разрешения коллизий — метод открытой адресации.
Добавление ключа:
- Вычисляем значение хеш-функции.
- Если соответствующая ячейка свободна, записываем туда данные.
- Иначе пробуем записать в следующую по порядку свободную ячейку. Дойдя до последнего индекса, переходим к началу таблицы.
Алгоритм поиска элемента:
- Вычисляем значение хеш-функции.
- Если искомый элемент в этой ячейке, поиск окончен.
- Иначе продолжаем искать в следующих по порядку ячейках, пока не встретится пустая.
Удаление ключа чуть сложнее. Нельзя просто удалить данные из ячейки, ведь следом могут быть записаны ключи, которые попали не в свою ячейку. Тогда при операции поиска алгоритм остановится, встретив пустую ячейку. И данные, которые на самом деле присутствуют, не будут найдены.
Гоша: И что же делать?
Тимофей: Решение — помечать удаляемые ячейки специальным значением. Например, “deleted”.
Тогда при вставке нужно проверять “deleted” и вставлять элемент на его место, встретив “deleted”, продолжать алгоритм.
Гоша: А как справиться с этой проблемой?
Тимофей: Если количество таких ячеек превышает заданный лимит, нужно перезаписать данные заново в таблицу, но уже без ячеек, помеченных символом “deleted”.
Гоша: Да, логично. Я себя уже чувствую специалистом по хеш-таблицам!
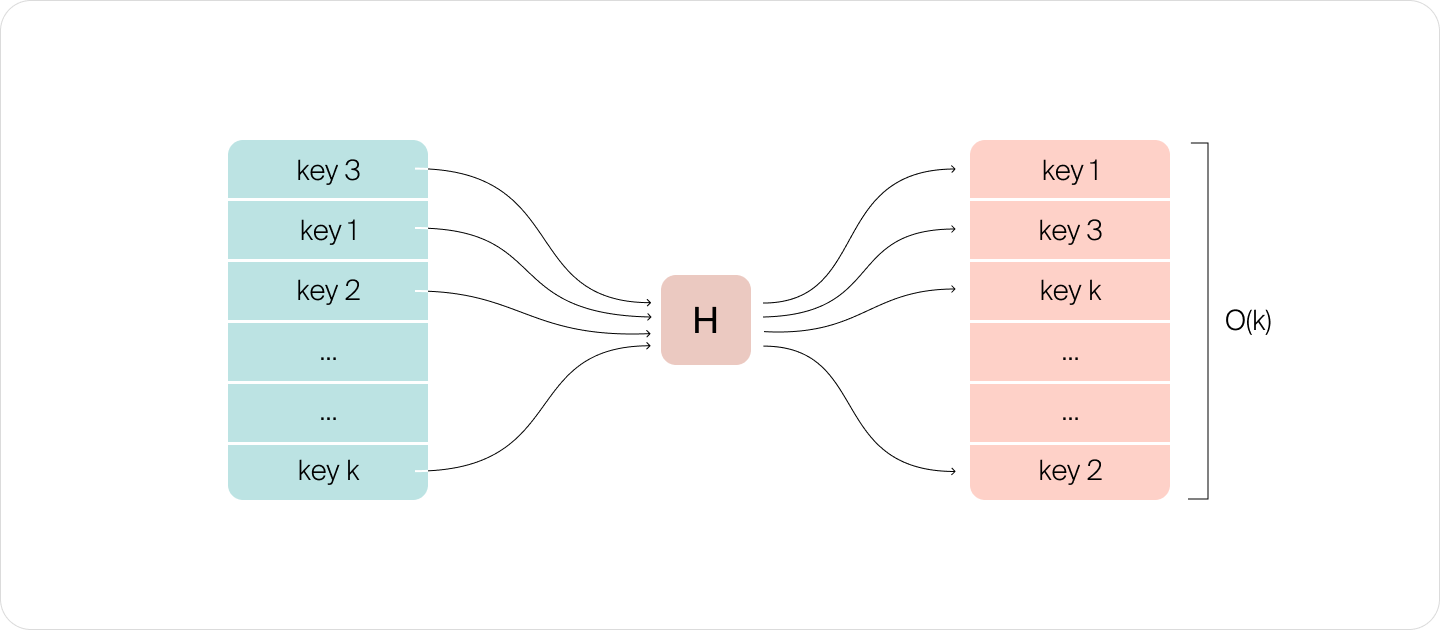
Тимофей: Рано тебя посетило это чувство.
Предположим, в таблице рядом записаны ключей. Тогда при попытке поиска или записи нужно проделать операций. Чем больше кластер, тем менее эффективным будет использование хеш-таблицы.
Гоша: Можно ли как-то с этим бороться?
Тимофей: Да. Но проблема в том, что на каждом шаге при попытке записи мы пойдём в следующую ячейку.
То есть — плохая стратегия.
Гоша: А какая хорошая, идти в предыдущую ячейку?
Тимофей: Нет. Вообще последовательность ячеек, куда мы хотим вставить элемент, — это перестановка чисел от 0 до , где — размер таблицы.
Нужно подобрать такую последовательность чисел, которая перебирала бы все значения, но не по порядку. Сделав проб, нужно попробовать вставить элемент в каждую из ячеек.
Рассмотренный алгоритм можно улучшить.
.
То есть будем ходить с некоторым шагом .
Гоша: А может быть любое?
Тимофей: Не любое, и должны быть взаимно простые. Иначе будем ходить по одним и тем же ячейкам.
Например, если и — чётное число, то в ячейки с нечётными номерами мы никогда не попадём.
Рита: Можно, например, брать в качестве m степень двойки, а в качестве — простое число.
Варианты, в которых мы делаем единичный шаг и шаг , относятся к методам линейного пробирования.
Рассмотрим метод квадратичного пробирования.
В этом случае разные итерации пробирования двух элементов шагают по-разному.
Гоша: А как подобрать коэффициенты и , чтобы покрыть все ячейки, сделав проб?
Рита: Можно вот так: .
Тимофей: .
Алла: Как же с этим бороться?
Тимофей: Поможет двойное хеширование.
Будем ходить с шагом, индивидуальным для ключа. Даже если для двух ключей совпадёт, то вероятность совпадения для них очень маленькая.
Гоша: А как в этом случае обеспечить перебор всех ячеек?
Тимофей: Шаг, как и ранее, должен быть взаимно простым с размером таблицы. должна быть нечётной, а можно брать произвольной.
Время работы хеш-таблицы с использованием метода открытой адресации:
В лучшем случае: .
В худшем: .
В среднем: , где — коэффициент заполненности таблицы.
Решите задачи F, G: https://contest.yandex.ru/contest/19095/problems/F