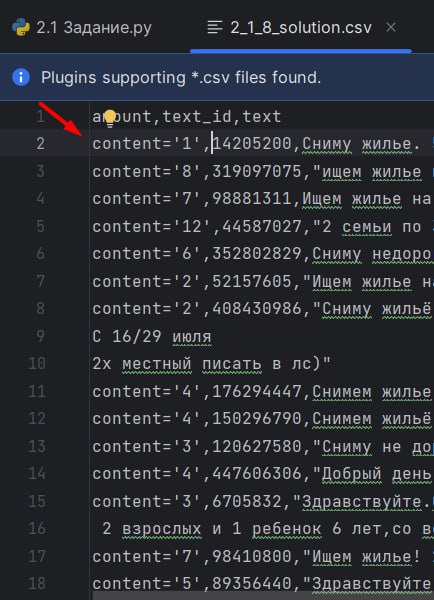
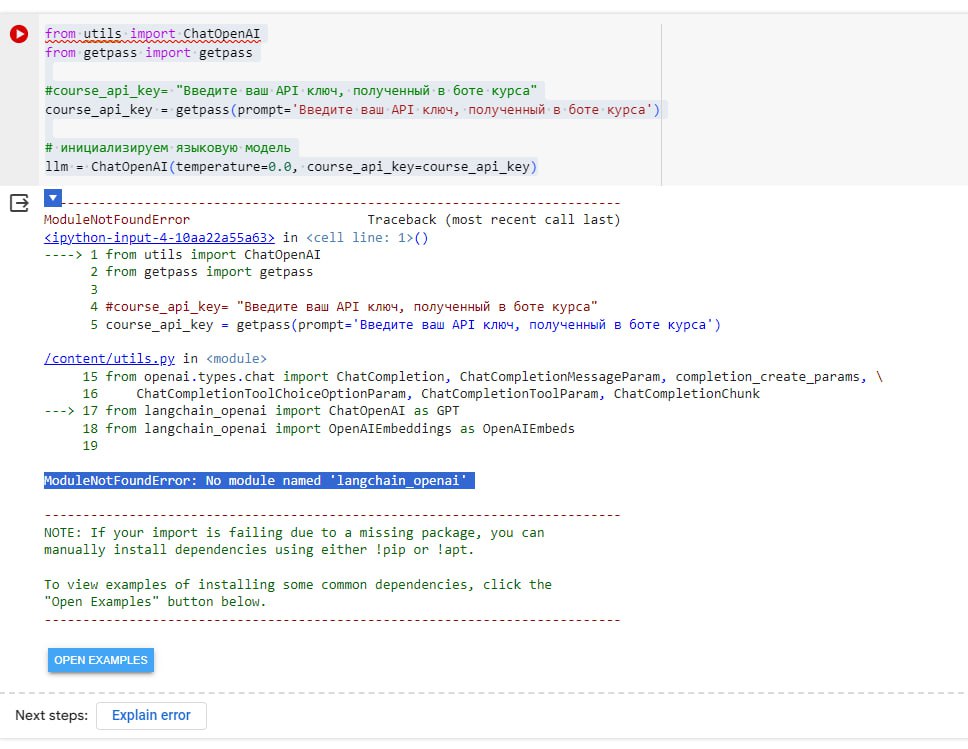
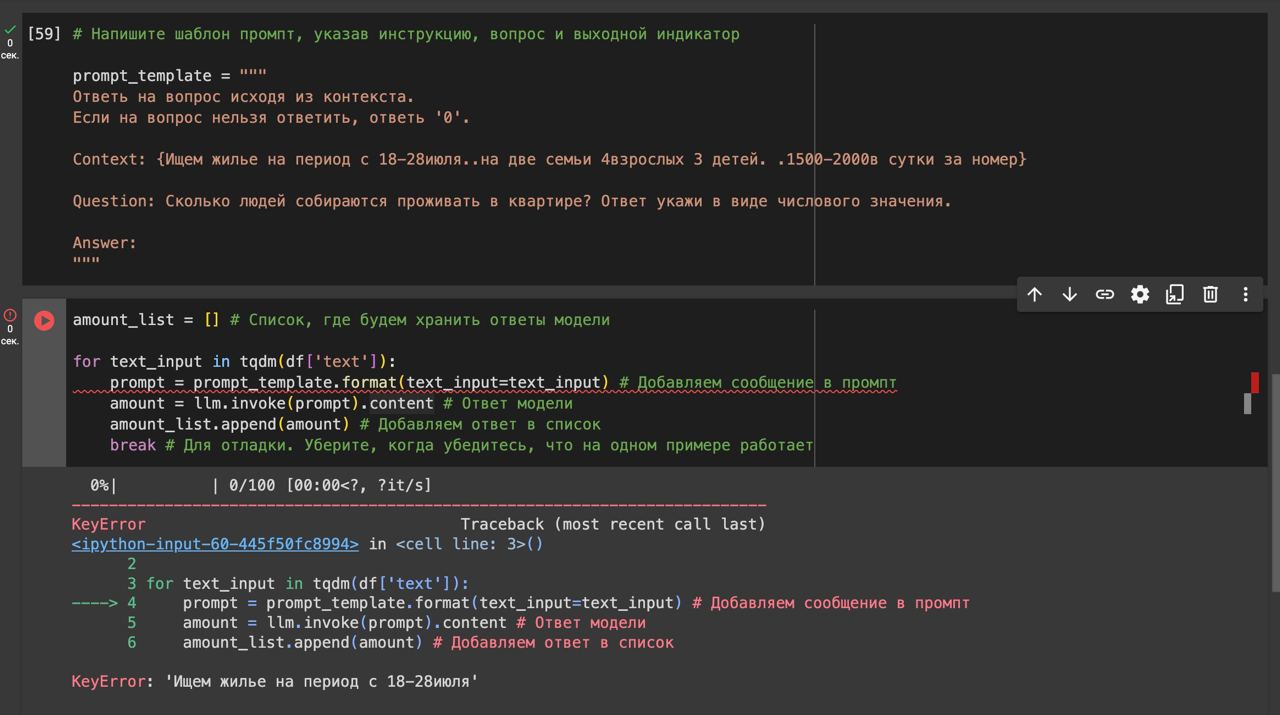
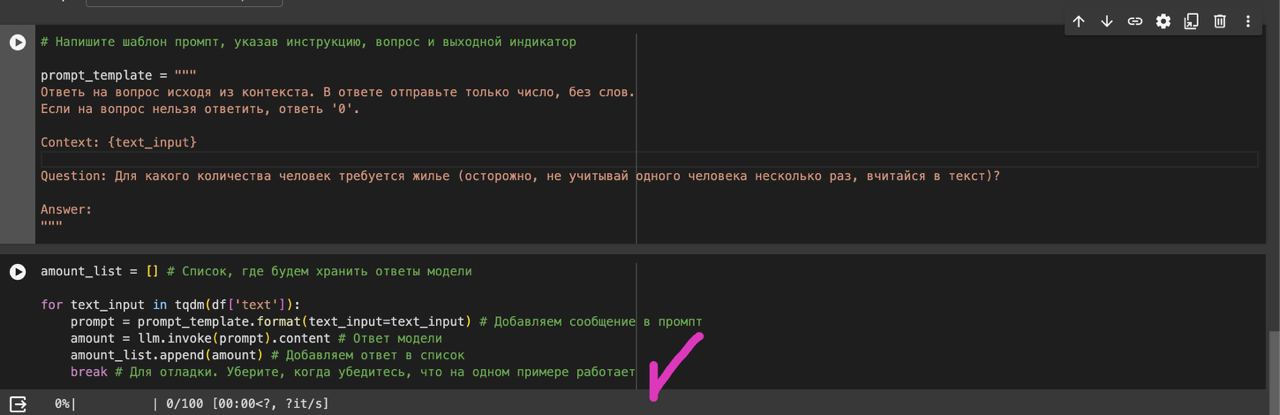
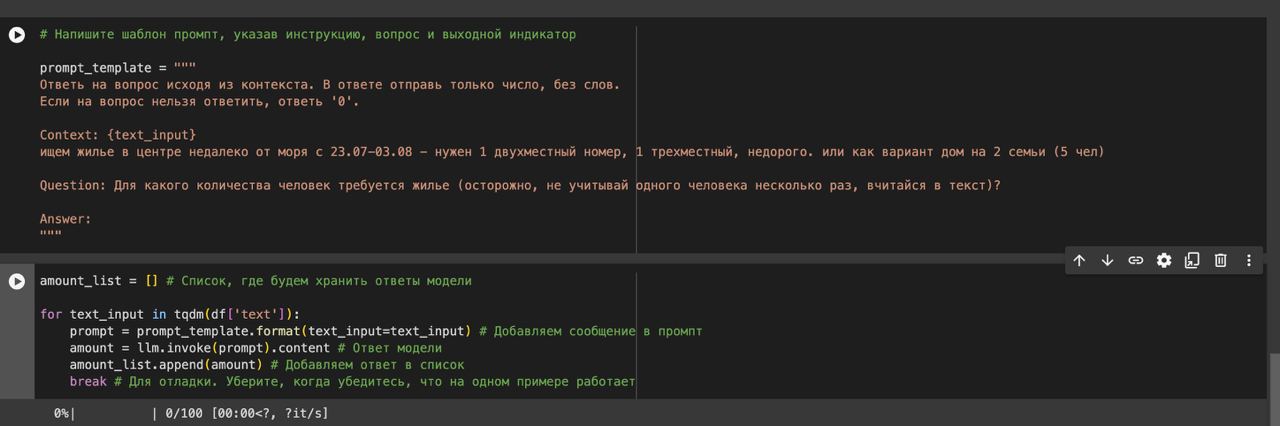
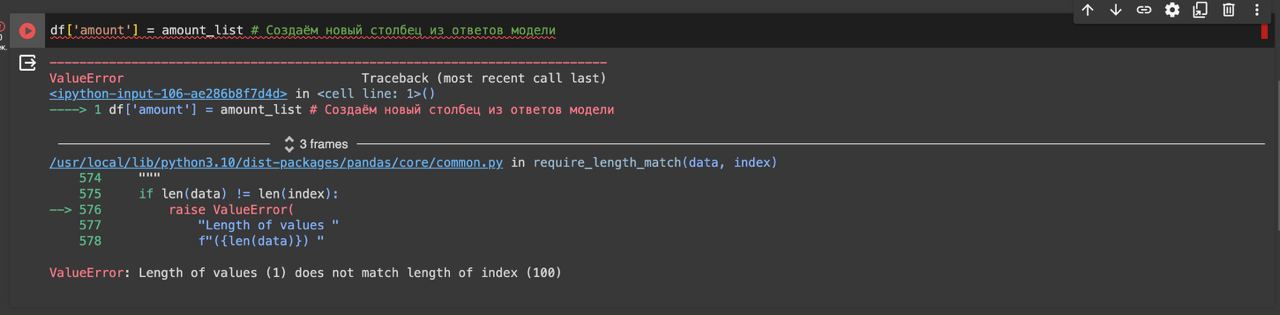
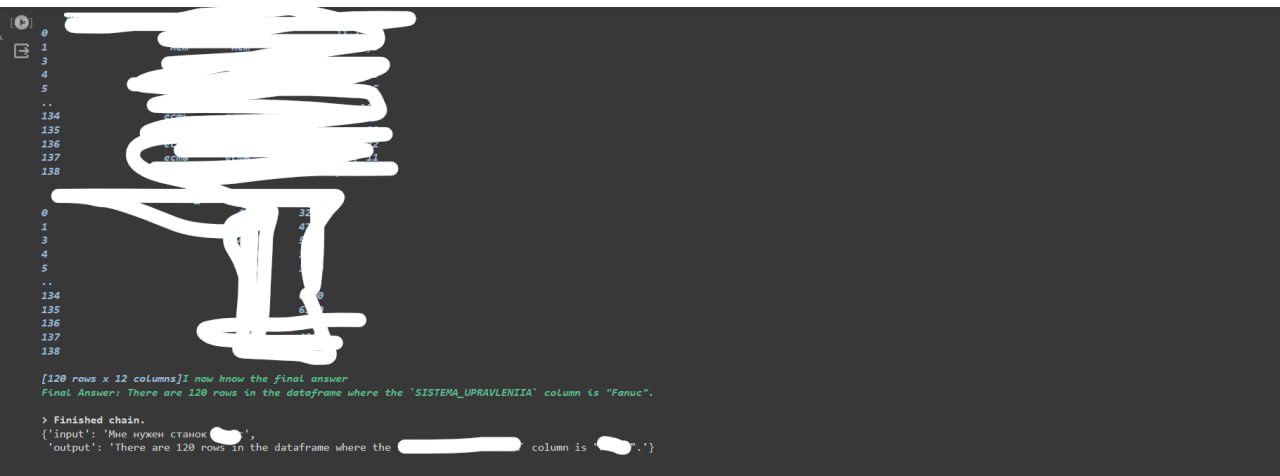
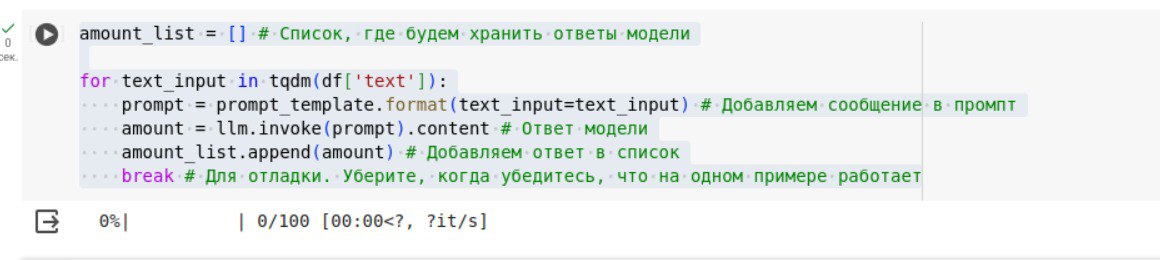
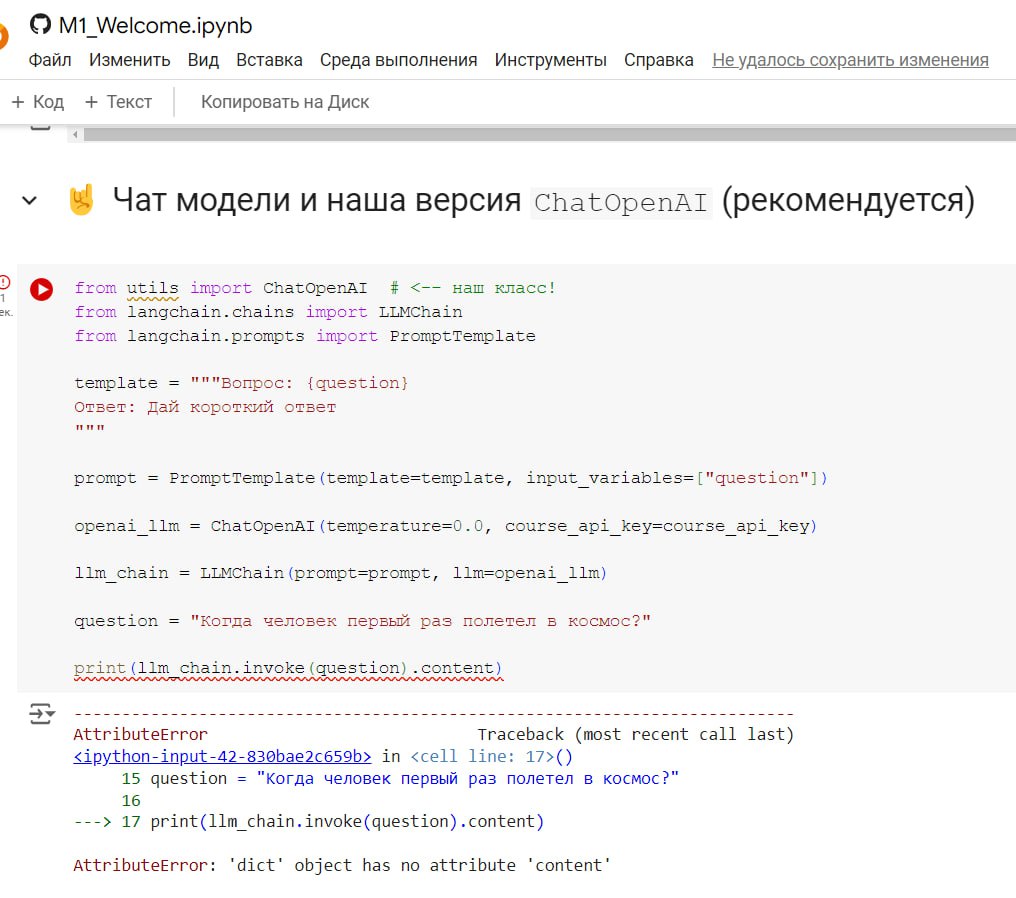
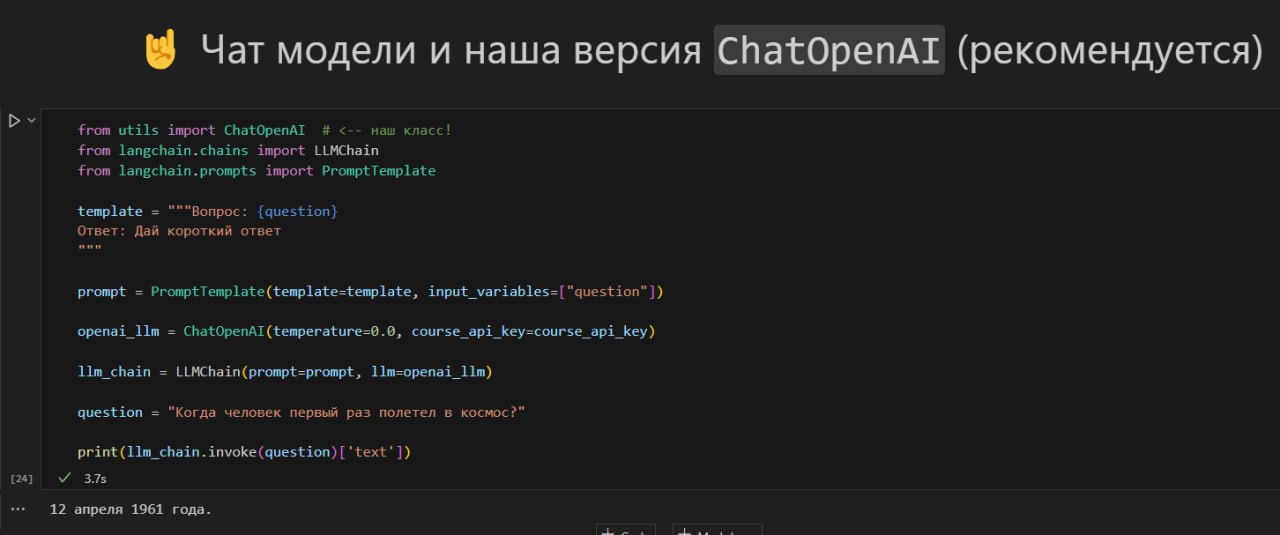
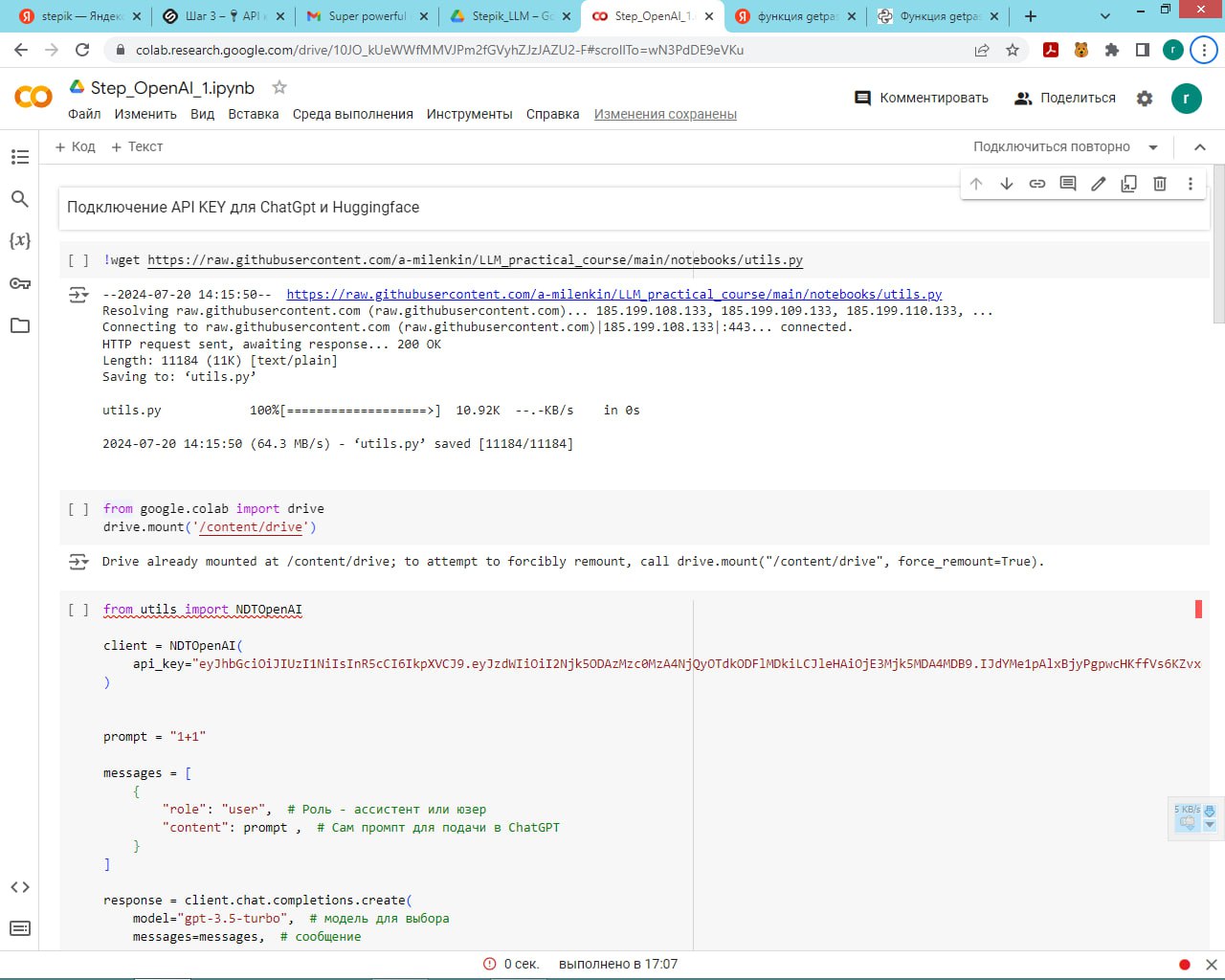
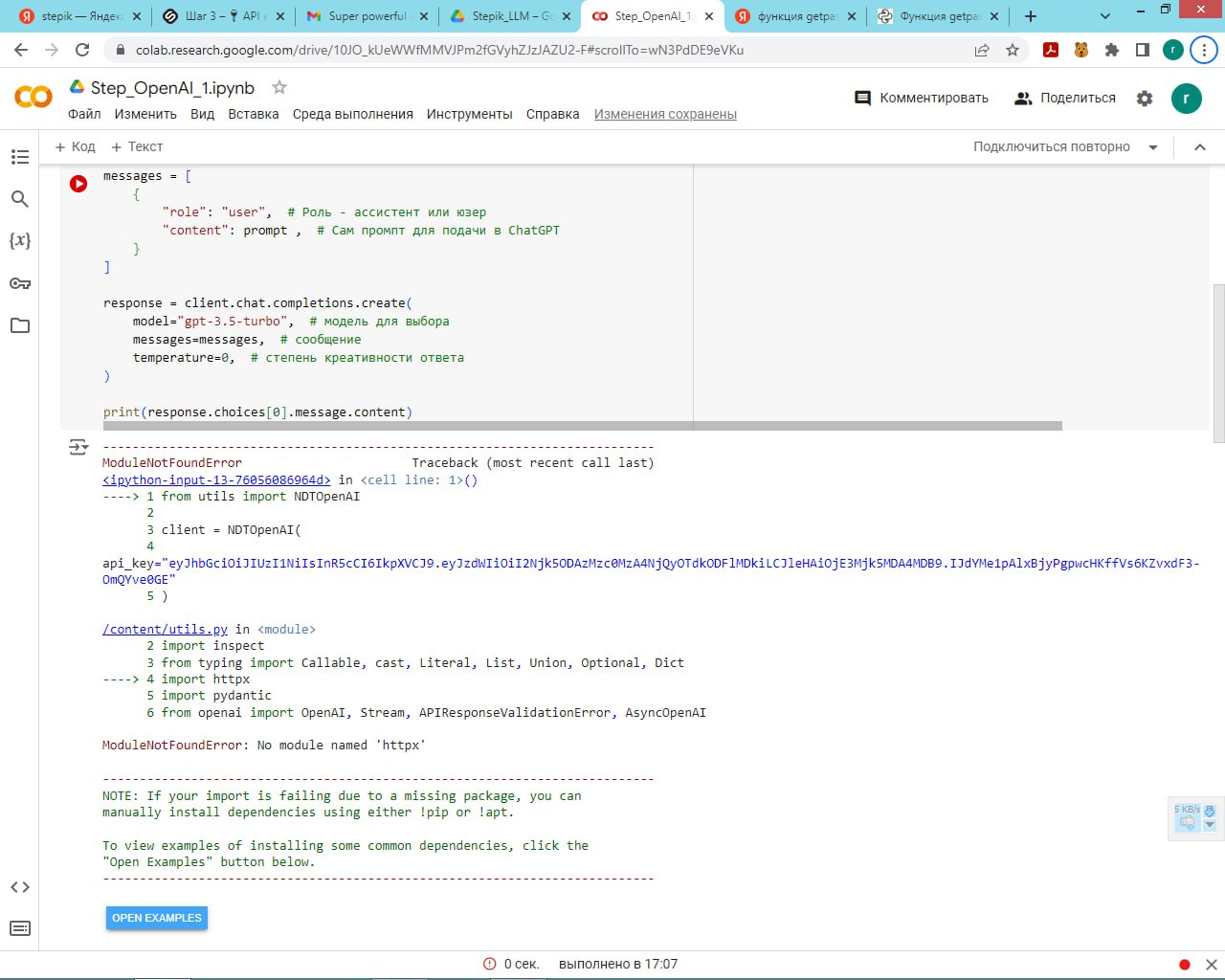
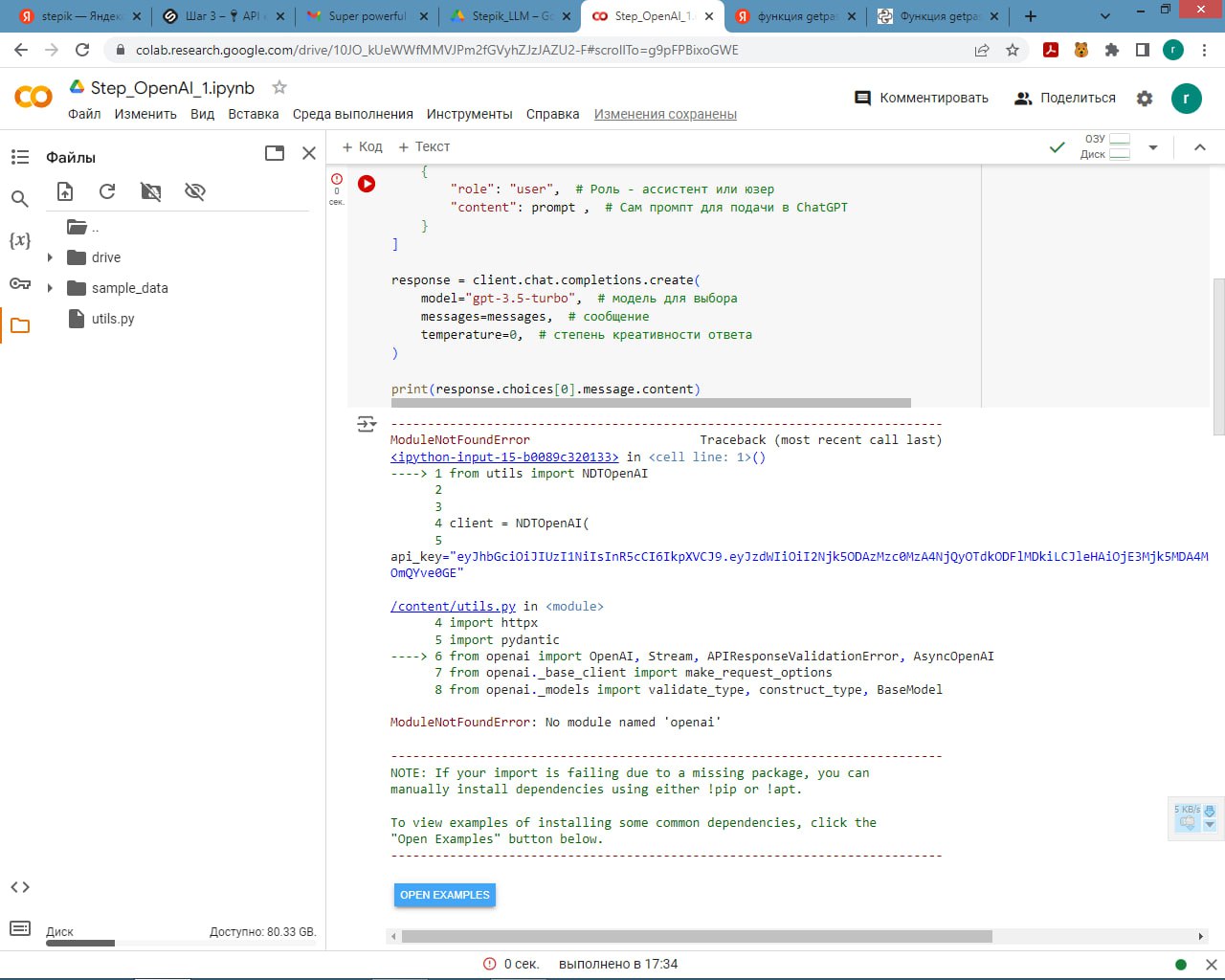
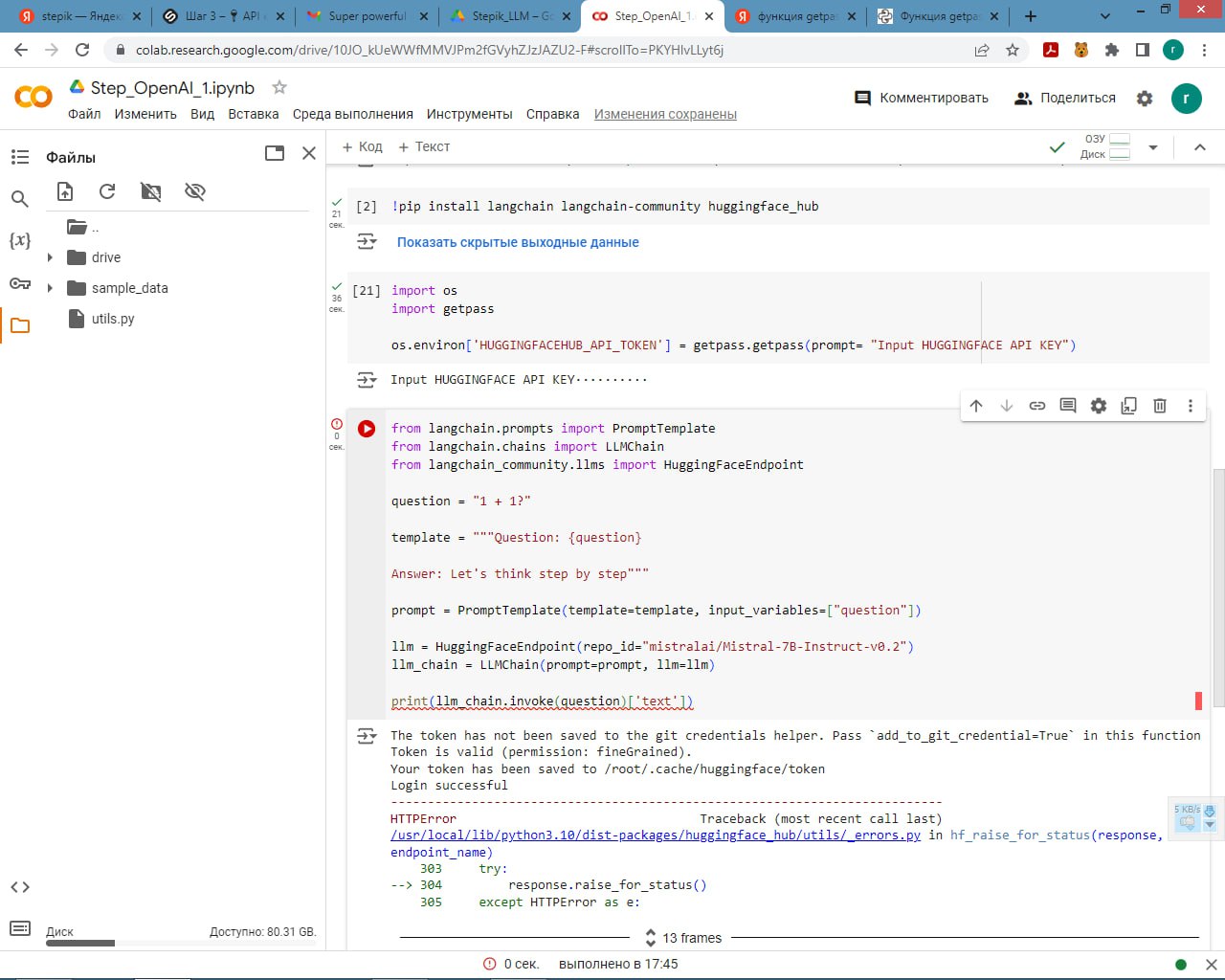
Подскажите пж по задаче 2.1
Только у меня проблема, что чатпгт добавляет в столбец amount значение content='число'?
Извращяюсь как могу, не нашёл где это настроить
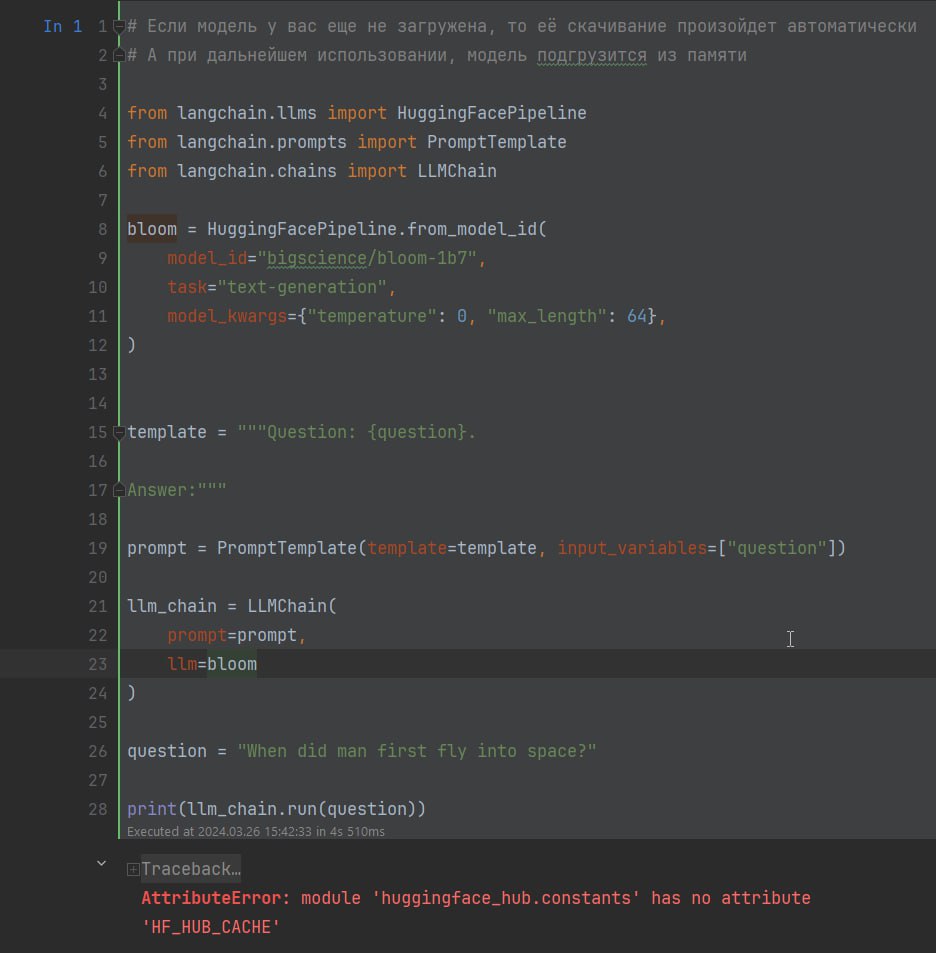
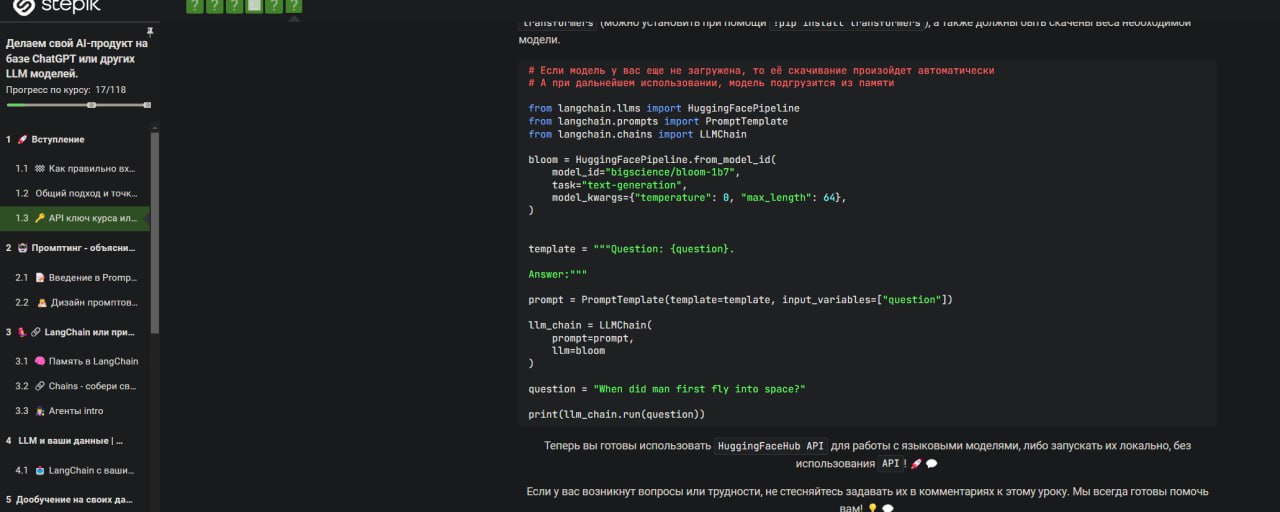
# Преобразуем значения столбца amount к
строковому формату
df['amount'] =
df['amount'].astype(str)
# Удаление лишних символов
из строки и преобразование к числовому формату
try:
df['amount'] =
df['amount'].str.replace("'",
"").str.split('=').str[1].astype(int)
except
ValueError:
df['amount'] =
df['amount'].apply(lambda x: np.nan if x ==
"'Я не знаю'" else x)
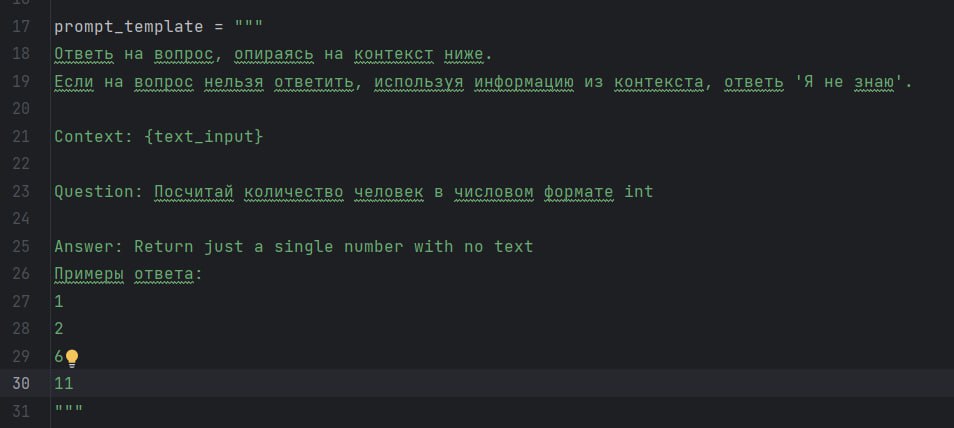
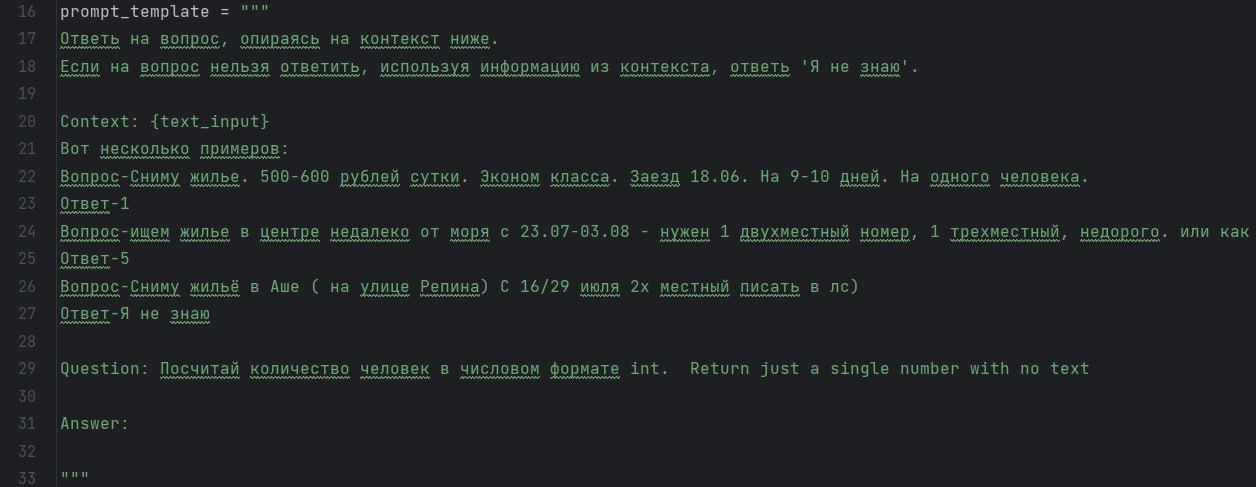











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}