Поясняем за промпты 🩻

В этом уроке разберемся с основным шагом взаимодействия с генеративными моделями - написанием промпта.
Грамотно составленный промпт поможет превратить генеративную модель из забавной
игрушки в рабочий инструмент, способный приносить пользу, экономить время и даже
генерировать профит. Далее, продвигаясь в изучении более сложных сценариев и
инструментов взаимодействия с LLM, вы убедитесь, что под капотом любого
навороченного инструмента лежит специально спроектированный промпт. Поэтому стоит
сосредоточенно пройти этот модуль, чтобы заложить фундамент для понимания дальнейшего
материала.
Ноутбук урока (Colab - то же самое что ноутбук урок, но в Colabe)
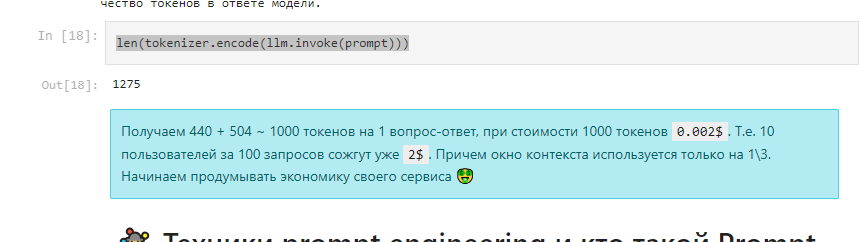
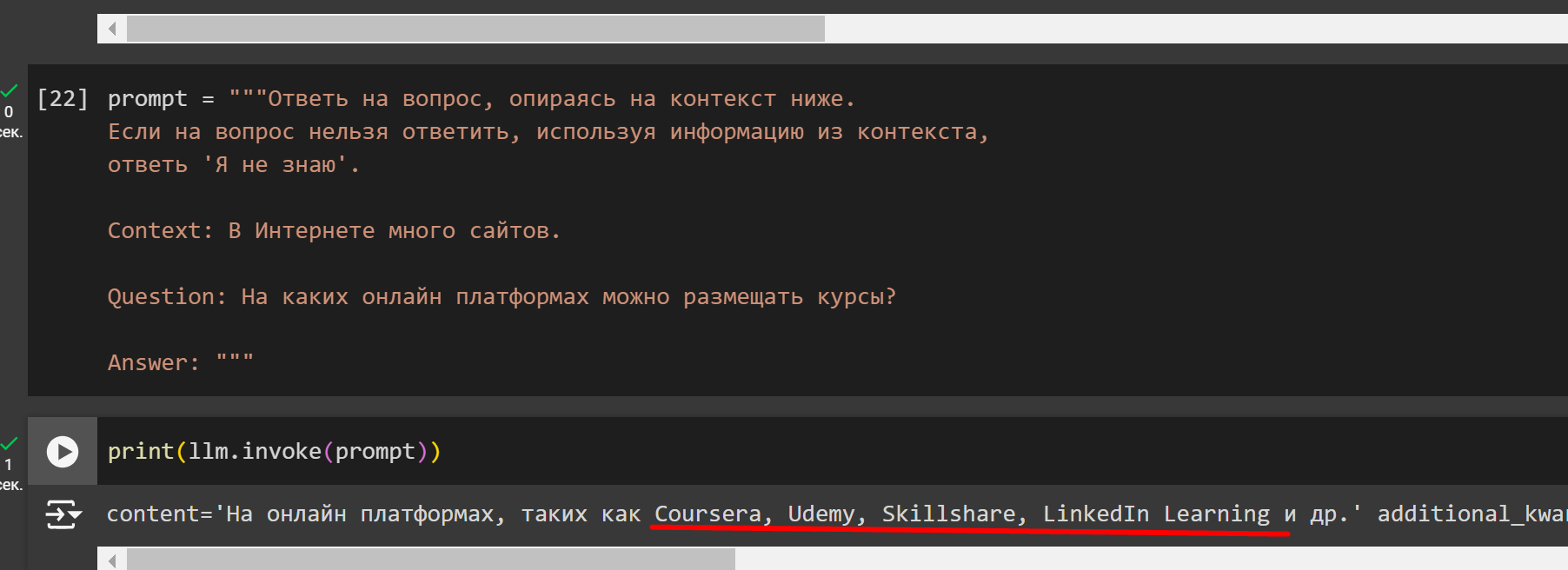
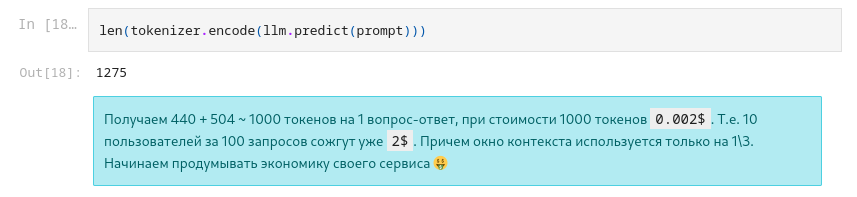
Пожелания по colab тетрадке: вынести определение используемой модели (openai или апи курса) в самый верх и в остальных ячейках через проверку флага использовать нужную модель. Я пользуюсь api openai и мне пришлось из всех ячеек удалять course_key
@Игорь_Суслов, про какой колаб речь? Для решения задач?
@Иван_Александров, нет, про ноутбук урока https://colab.research.google.com/github/a-milenkin/LLM_practical_course/blob/main/notebooks/M2.1_Prompt_Engineering_intro.ipynb - т.е. примеры из него нельзя потыкать с ключом openai без доп приседаний
@Игорь_Суслов, да, неудобно. Посмотрим, как можно поправить.