LLM — сила 💪, ML — могила 🧟
Как Вы понимате, решить любую ML задачу можно двумя путями. Один из них — это
использовать классические ML подходы для которых нужная разметка — рабочая тактика.
Экономный путь. Однако есть и другой путь — использовать мощь LLM!
Для этого надо будет изучить несколько техник написания промптов с инструкцией. Может
показаться, что LLM - это чисто хайп, но если вы посмотрите на практике
какие задачи умеют решать LLM архитектуры, то у вас волосы дыбом встанут
от их крутости. Цель этого шага потренироваться решать такие задачи. Искать
Gold инструкции сложно, когда ты не уверен, что они вообще
существуют. В этой задаче мы гарантируем, что они есть!
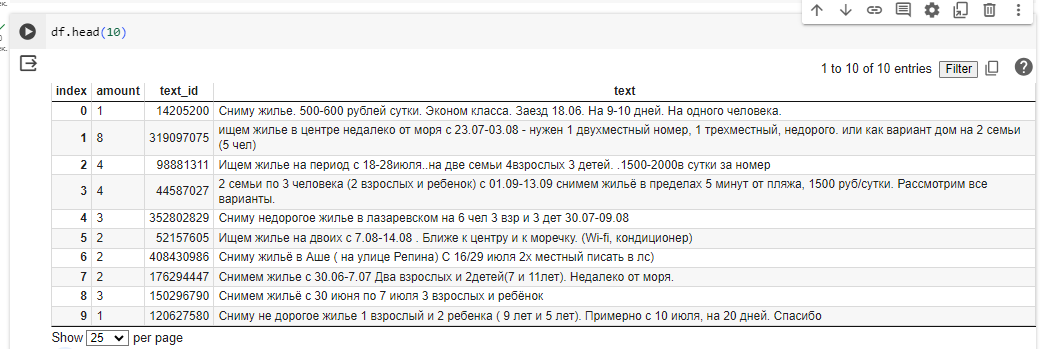
Задание: Вам дана выборка реальных текстовых заявок на жилье,
которая состоит из 100 строк. В каждой заявке есть информация про число человек. Если
взглянуть на эти тексты, то уже понятно, что автоматичеки вытащить число человек из
заявки будет не просто. Тем не менее, это вполне реально. Попробуйте
написать такой промпт с инструкцией, чтобы ваша точность была выше 80%. В этой задаче
не подразумевается использование сторонних ML библиотек, кроме API
ChatGPT и pandas. Хватает всего нескольких строк, чтобы
решить эту задачу очень качественно.
Раскрыть:
path = 'https://stepik.org/media/attachments/lesson/1084297/submission100lines.csv'
df = pd.read_csv(path)Файл для прогнозирования с помощью ChatGPT. Ссылка на файл (локальный файл).
Замечание: В вашем решение должно быть верно
минимум 50 ответов
Что на выходе? csv файл, содержащий три столбца -
amount, text_id, text.
(Столбец amount должен быть числового типа)
COLAB ноутбук (локальный файл) в котором всё готово для удобного начала решения задачи!



Добрый день!
Единомышленники, делюсь наблюдениями.
Чтобы решить задачу неитеративно, нужно написать достаточно детализированный промт (свои изыкания изложил в разделе "Решения"), в который стоит включить:
1. Ясные и точные указания на то, как нужно анализировать текст заявок. Это помогает Модели точно понимать задачу и фокусироваться на важных деталях.
2. Конкретные примеры с ответами, которые позволят Модели лучше понять, как именно следует интерпретировать разные типы данных в заявках.
3. Учет различные сценарии, включая ясные указания, упоминания групп, сочетание взрослых и детей, а также неопределенные формулировки, что обеспечит гибкость и адаптивность Модели к разнообразным ситуациям.
4. Логические проверки, которые помогут избежать неправильных ответов в случаях, когда Модель правильно идентифицировала часть информации, но сделала неверный вывод.
5. Обработку неопределенности. Промпт руководит Моделью, как обращаться с нечеткой или неполной информацией, подчеркивая важность оценки контекста и использования обоснованных предположений.
Полученный, таким образом, промт будет достаточно ресурсоемким, в моем случае получилось так:
Для предварительного расчета использованных токенов использовался рекомендованный на Курсе энкодер
'p50k_base'и библиотекаtiktoken. Однако следует учесть, что эти расчеты являются приблизительными. API OpenAI использует свои метрики для оценки расхода токенов, которые зависят от множества факторов, включая сложность текста, частоту слов и даже структуру предложений. Таким образом, реальное количество токенов, потребляемых при взаимодействии с моделью, может отличаться от представленных расчетов, что важно учитывать при планировании бюджета при использовании API OpenAI.Поэтому, как верно указал в начале Курса Александр Миленькин - "начинаем прикидывать экономику Проект..."
Удачи!
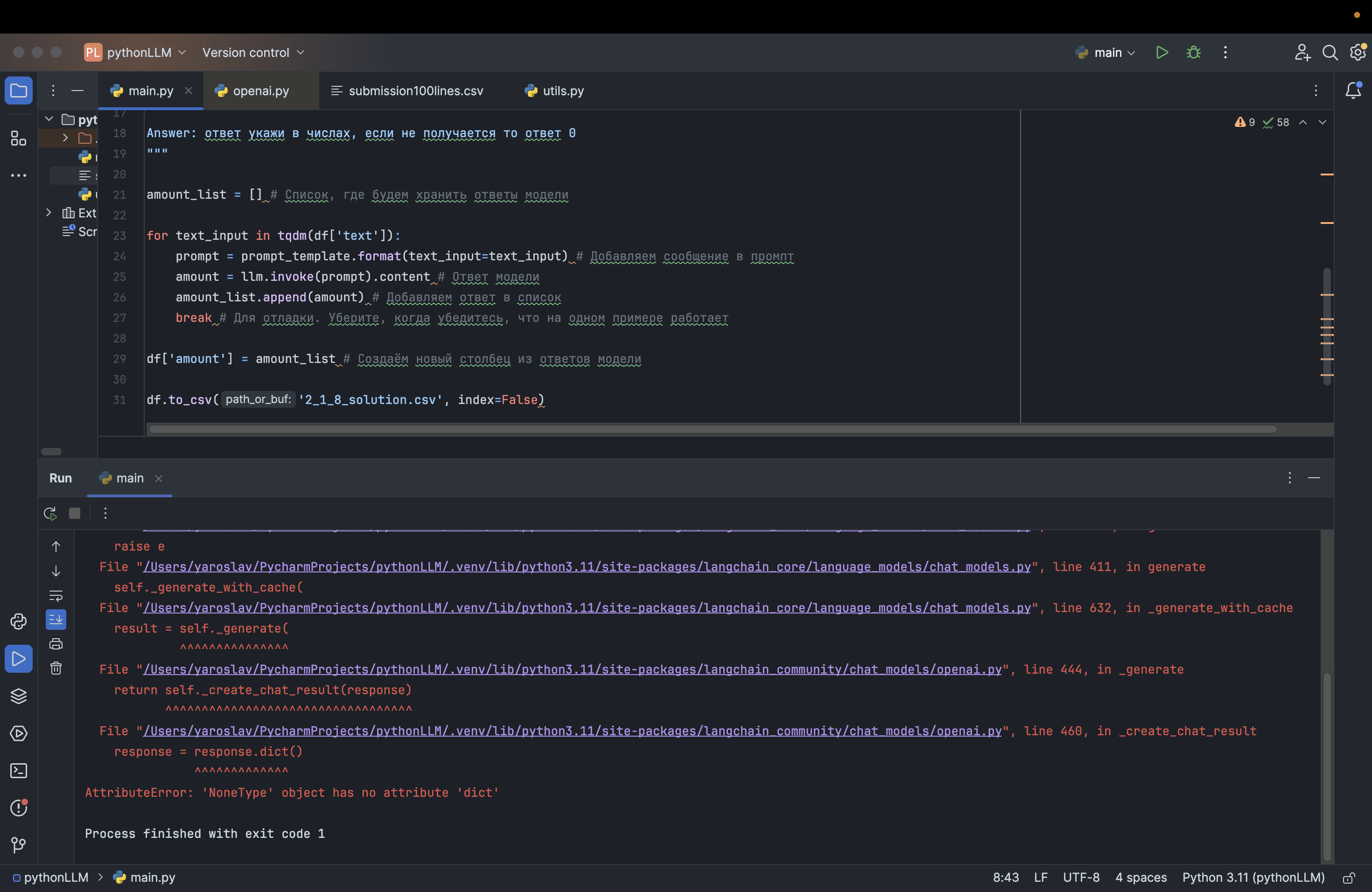
@Морозов_Валентин, спасибо за подробный комментарий!