Файнтюнинг LLM
Файнтюнинг больших языковых моделей (fine-tuning LLM) - это обширная тема с огромным разнообразием техник и подходов, которая заслуживает отдельного большого курса. Ниже проиллюстрирована основная палитра методов файнтюнинга:
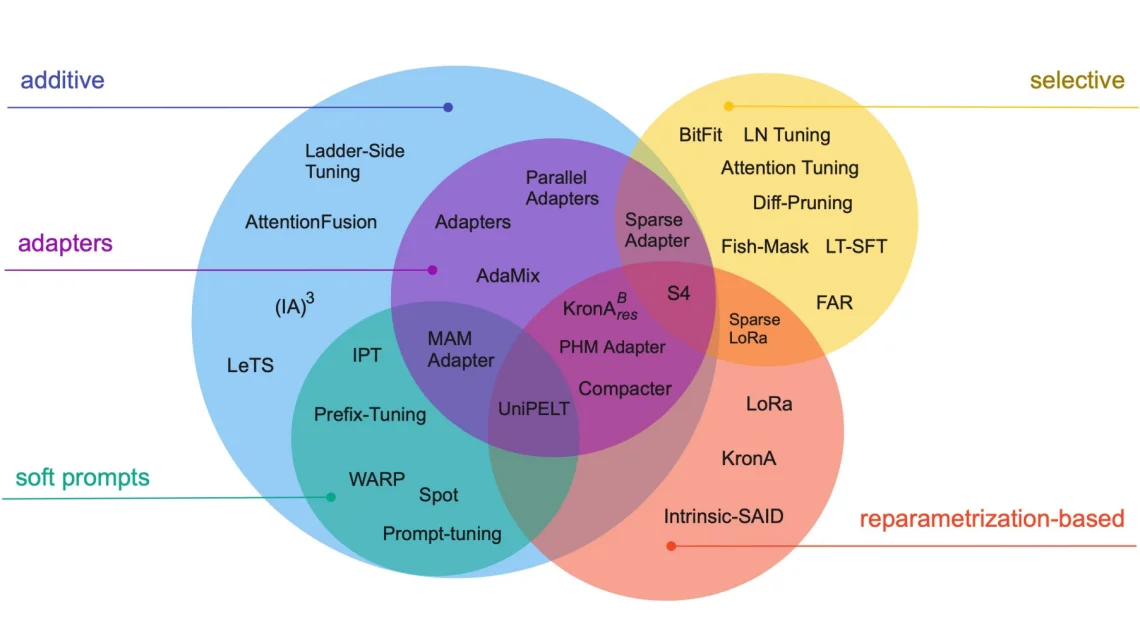
Чтобы разобраться во всём этом многообразии не хватит одного урока т.к многие из
этих методов подразумевают доступ к мощным серверным видеокартам (типа A100, H100) c
огромным количеством видеопамяти, а так же время на сбор качественных датасетов на
миллиарды токенов. Мы разберем самый доступный и часто применяемый в небольших
приложениях метод файнтюнинга - PEFT. И его самую
популярную разновидность LORA. Так как в нашем арсенале только
потребительские видеокарты или бесплатные ресурсы Colab, а мы хотим тюнить модельки
по-жирнее, то чаще всего будем пользоваться её разновидностью для квантизованных
моделей QLORA.
В этом уроке ...
- Когда и как файнтюнить (fine-tuning) LLM модели или достаточно RAG?
- Какие есть варианты подготовки данных для файнтюнинга?
- Узнаем, как файнтюнинг поможет улучшить производительность LLM в доменных задачах
- Разберем режим обучения c инструкцией - instruction fine-tuning
- Поймем что такое
PEFT, и кто такиеLoRAиQLoRA. - Как
PEFTснижает вычислительные "косты" и решает проблему забывания?