Instruction fine-tuning
 Zero-shot, few-shot, RAG подходы имеют свои недостатки. Например,
ограниченность контекста в промпте или модель просто не понимает, что от неё хотят,
если она не такая большая. Тогда можно рассмотреть
Zero-shot, few-shot, RAG подходы имеют свои недостатки. Например,
ограниченность контекста в промпте или модель просто не понимает, что от неё хотят,
если она не такая большая. Тогда можно рассмотреть
instruction fine-tuning.
Файнтюнинг - это процесс обучения на размеченных данных (пары промпт - генерация) и
обновлением весов LLM. Достаточно 500-1000 примеров для файнтюна на одну задачу. Ещё
fine-tuned LLM называют Instruct LLM, так как они
дообучаются на инструкциях (как мы разбирали в прошлом уроке).
Первое, что нужно сделать перед началом файнтюна это собрать датасет для обучения или
использовать уже готовый, всё с того же HugginFace.
Собрать свой датасет можно различными способами:
- с помощью pandas
- преобразованием python-словаря в json
- да даже просто в Excel.
- Или с помощью специальной библиотеки для этих целей.
Например, PromptSource - библиотека для контроля версий промптов, и подбора готовых промптов для различных задач и датасетов. Так же в ней есть удобная интеграция с бенчмарками и HugginFace.
В этом уроке рассмотрим:
- использование готового датасета с HuggingFace (оформили в виде статьи на Хабр)
- сборку своего датасета с нуля на основе постов ТГ-канала (ноутбуки урока)
Fine-tuning на несколько типов задач 🍮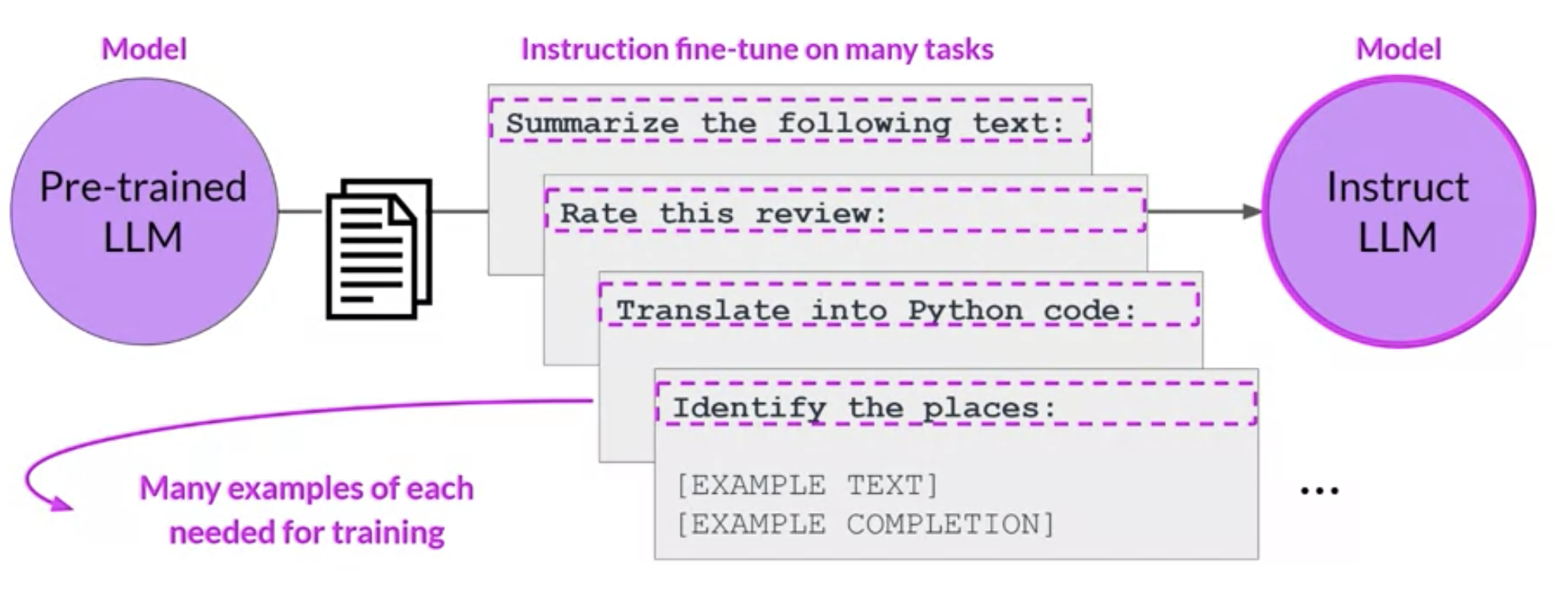
В этом случае для каждой задачи нужно 500-1000 примеров, что является основным недостатком такого подхода.
Есть даже такое семейство моделей, которые были обучены на многозадачных инструкциях. Это семейство называется FLAN (Fine-tuned LAnguage net)
Например:
- FLAN-T5 - это instruct LLM для базовой модели T5. Она была зафайнтюнена для 473 датасетов на 146 различных категорий задач.
Но будьте осторожны!
Если ваш файнтюн состоит из одного типа задач, то LLM-ка может забыть как решать остальные задачи. Так мы подошли к проблеме забывания, об этом в следующем стэпе.