Мотивация файнтюна (тонкой настройки) 👉👈⚙️
Изначально в весах LLM закодировано много информации об окружающем мире. Как правило, модель разбирается в разных вещах, но не знает, как верно реагировать на наши вопросы, промпты. Когда даем какую-то специфическую задачу, в модели изначально не заложено знание о том, как её решать, чтобы это удовлетворило пользователя. Таким образом, файнтюн помогает дообучить модель новым конкретным навыкам именно под наши запросы.
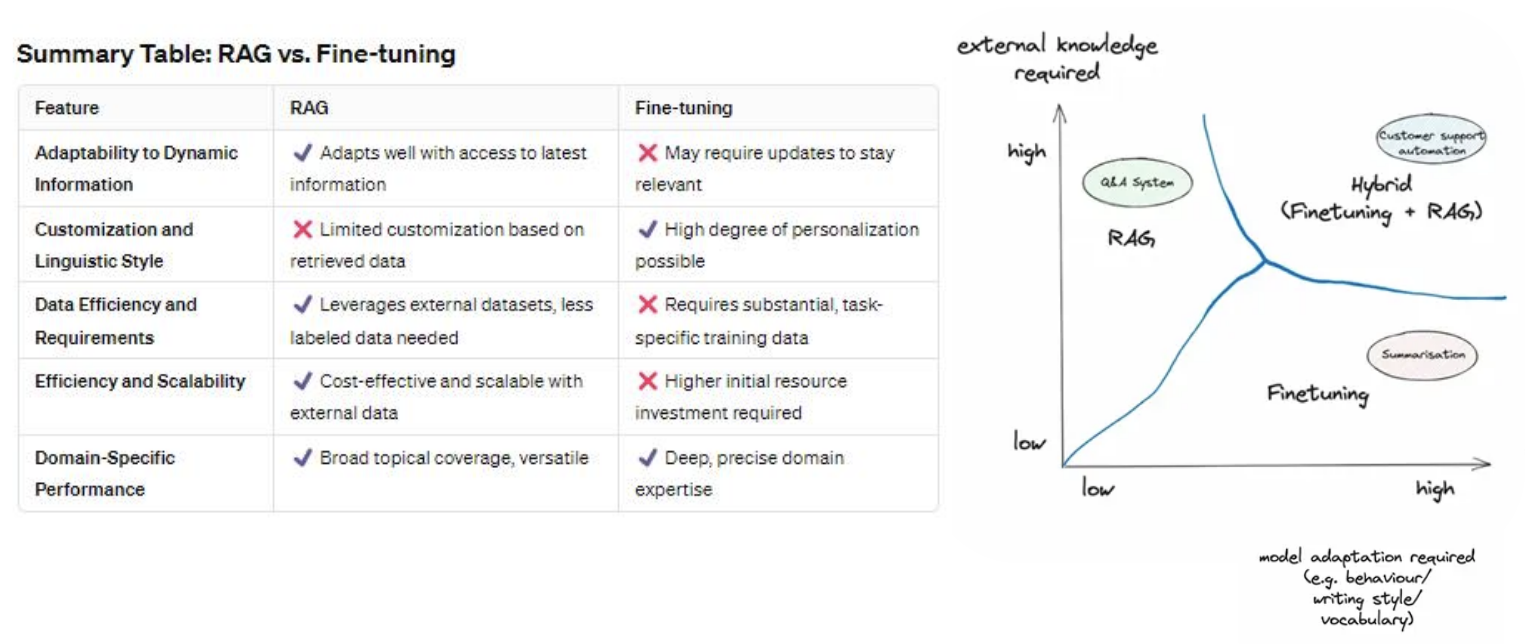
Преимущества FT по сравнению с RAG?
| Плюсы | Минусы |
|---|---|
|
Более консистентные результаты генерации (например, можно передать авторский стиль) |
Нужно собрать гораздо больше данных (самая трудоемкая и важная часть) |
| Можно натренировать под специфический юзкейс | Повышенный порог входа - нужны более глубокие технические знания |
| Не забывает данные (хранятся в весах модели) | Нужно больше ресурсов и времени на старте |
| Можно передать больше данных, чем в RAG (т.к. нет ограничений контекстного окна) | Необходимость переучивать при выходе новых версий модели |
| Приватность - данные не передаются открыто в промпте, а "зашиты" в весах (меньше возможностей для промпт-хакинга) | Не подходит для часто изменяющихся данных |
Допустим, вы взвесили все "за" и "против". И вам все-таки предстоит дообучить LLM. Одна из проблем, которую вы встретите - это забывание информации. В ходе полного файнтюна базовой модели (переобучения всех параметров модели) можно научить решать одну задачу по инструкции, но LLM может забыть почти всё, что знала раньше, и не сможет ничего ответить на другие запросы.
PEFT(Parameter-Efficient Fine-Tuning) - это частичный файнтюн, суть
метода в заморозке большой части весов, чтобы сохранить General knowledge, и дообучить
оставшуюся малую часть параметров под нашу задачу. Также PEFT позволяет проводить
файнтюн с меньшими затратами временных и вычислительных ресурсов. Делать это можно
разными способами: самый популярный вид PEFT - это
LoRA(Low-Rank Adaptation) , для квантизованных моделей
QLoRa, с помощью которой можно файнтюнить модель даже на процессоре.
Подробнее почитать про PEFT, LoRA, другие методы и попытаться понять почему это работает можно в статье на Хабр.
Решения проблемы забывания 🤷
- Первый вопрос, который вы себе должны задать: устраивает ли вас то, что ваша LLM умеет решать только одну задачу. Если да, то можно не беспокоиться об этой проблеме.
- Естественно, логичным решением будет fine-tune на несколько видов задач, но это потребует больше примеров (500-1000 на каждую задачу) в сумме и больше вычислительных и временных ресурсов для дообучения.
- Прибегнуть к
PEFTвместо полного файнтюна всех весов модели - самый часто используемый вариант для небольших сервисов и MVP. Метод с низким порогом входа по как по вычислительным, временным, финансовым ресурсам, так и по техническим знаниям ( с применением специальных файнтюн-фрэймворков).
Какая проблема может возникать в ходе fine-tuning LLM?