💼 ChatGPT - ваш ручной карьерный
консультант
Вы решили найти новую работу и подписались на множество различных тематических чатов и рассылок. Теперь у вас каждый день собирается такое огромное количество вакансий, что обрабатывать их вручную займет много времени.
На помощь здесь снова придет ChatGPT - напишите такой промпт, с помощью
которого получится вытягивать нужные значения из описания вакансии, а потом соберите и
сохраните полученную информацию в csv файл.
Информация, которая вам необходима, поместится в 5 колонок:
1️⃣ Позиция (job_title).
- Как указано в описании вакансии, на том же языке. Проверяем полное совпадение, без учета регистра.
- Если написан грейд, его нужно убрать (например,
SeniorPython developerPython developer,C++ разработчик->(middle, senior)C++ разработчик).
2️⃣ Компания (company).
- Как указано в описании вакансии, на том же языке. Проверяем полное совпадение, без учета регистра.
- Указываем только название (не пишем финтех, крупная компания, мобильная игра и т.д.).
3️⃣ Зарплата (salary).
- Числа пишем без пробелов, не пишем
тыс.илик.(умножаем в таком случае на 1000), не пишемфикс,плюшки,премии,% от продаж,техникаи т.д. - Не пишем
net,gross,на рукии т.д. - После числа (диапазона чисел) указываем валюту
руб.или$после пробела. - Если указан диапазон, то пишем его через тире, около тире пробелы не ставим
(например,
100к-150к рублей->100000-150000 руб.). - Если указана только нижняя граница (
от 2000$или100000+руб), то пишем это значение, используя словоот(например,100к+руб->от 100000 руб.). - Если указана только верхняя граница, то пишем это значение, используя слово
до(например,до 100к руб->до 100000 руб.). - Если зарплата указана за час, то в конце добавляем
в час.
4️⃣ Контакты для связи (tg).
- Указываем контакт в телеграмм, используя
@. Проверяем полное совпадение, с учетом регистра. - Если указано несколько контаков, то указываем их через запятую (не забывая про пробел после запятой).
5️⃣ Грейд (grade).
- Возможные значения
intern,junior,junior+,middle,middle+,senior,lead. - Если указано несколько значений, то пишем их через запятую в порядке возрастания.
Если информация по какой-то из колонок явно не указана в описании вакансии или
LLM не может ее найти, поставьте значение None.
Что на входе? Вам предоставляется датасет с двумя столбцами:
text_id (уникальный идентификатор вакансии) и text (описание
вакансии).
import pandas as pd
df = pd.read_csv('https://stepik.org/media/attachments/lesson/1110806/vacancies_messages_50.csv')Что на выходе? csv файл, содержащий семь столбцов -
text_id, text, job_title, company,
salary, tg, grade.
Что использовать? В этой задаче не подразумевается использование
сторонних ML библиотек, кроме API ChatGPT и библиотеки
pandas для обработки данных.
Замечание: Ваше решение будет зачтено, если в нём будет минимум 120
правильных определенных значений (всего их 250, т.к. в датасете 50 строк и 5 колонок
для проверки).
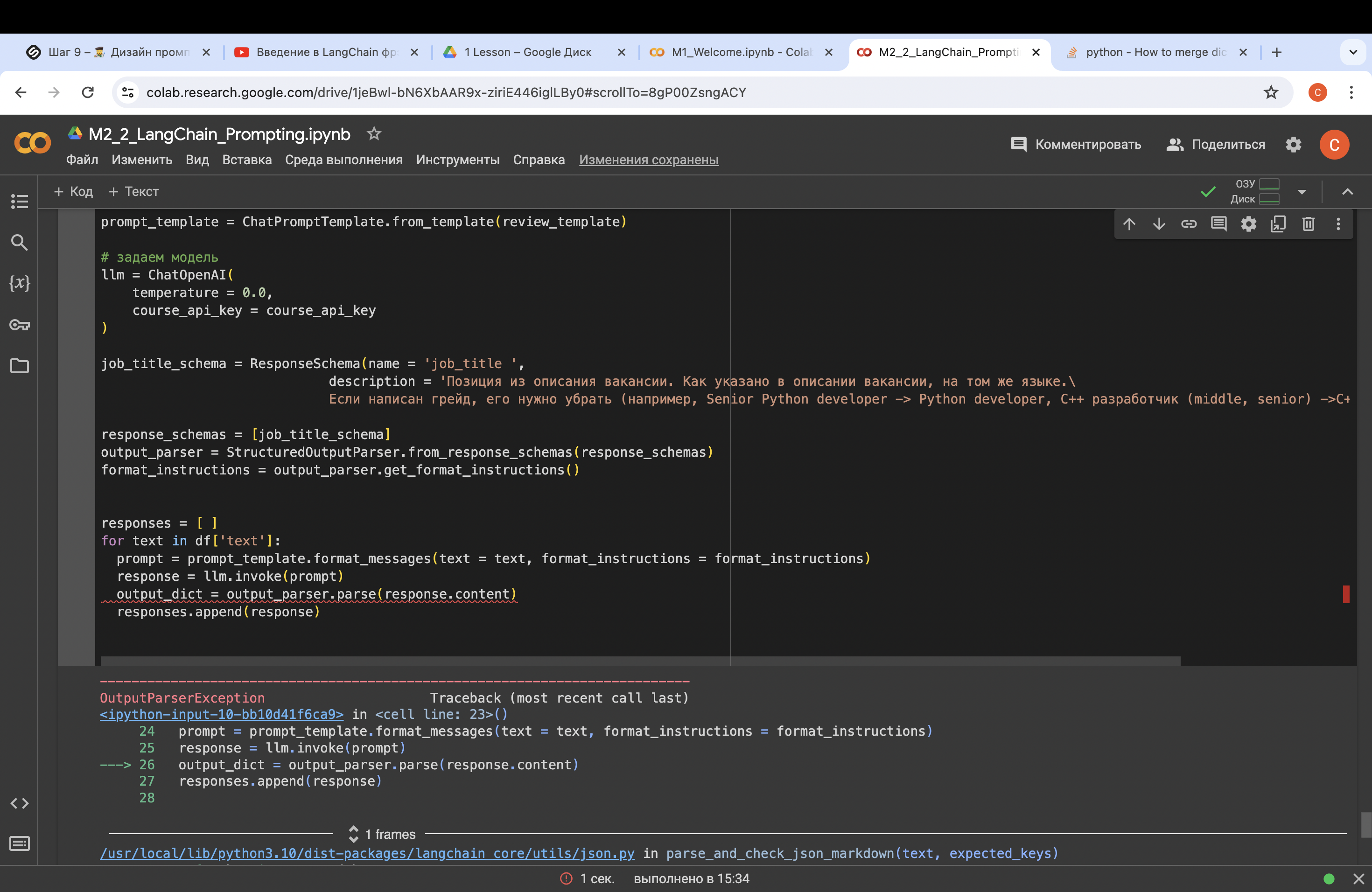
Добрый день!
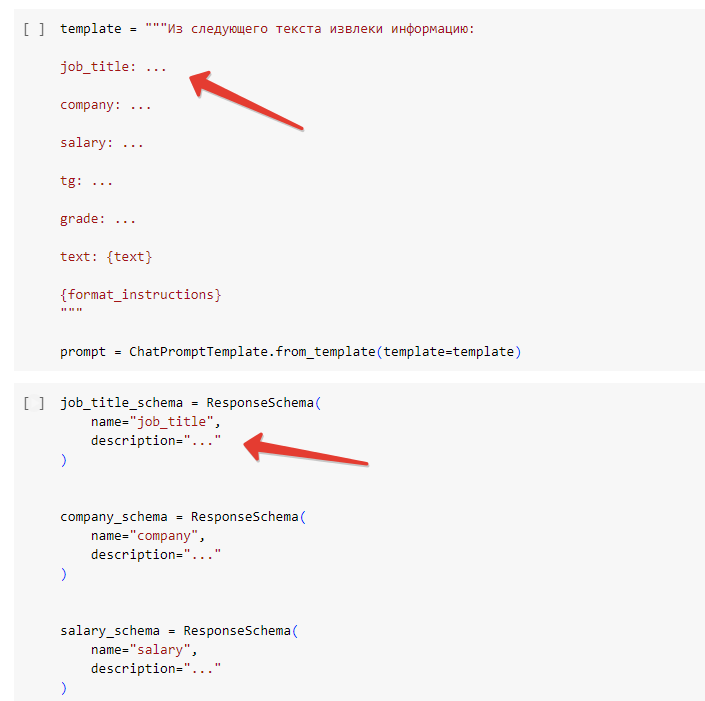
А я правильно поняла, что мы в template пишем тоже самое, что и в ResponseSchema? Что надо писать туда и туда?
@Мархай_Ольга_Сергеевна, не совсем. Template это шаблон промпта. А РеспонсСхемы мы передаём в аутпут парсер, чтобы ответ модели отформатировался в нужном нам формате. АутпутПарсер формирует нам FormatInstructions, которые мы передаём вместе с темплэйтом в промпт. Итоговый промпт, который подается в модель можете помотреть в нашем шаблоне так:
prompt.format_messages( text=df.text[0], format_instructions=format_instructions )Ещё можете ниже посмотреть подробный комментарий от Валентина Морозова.
@Иван_Александров, такой же вопрос, я не понимаю, нужно ли писать одно и тоже в template и response_scheme? Или описание нужно писать где-то в одном месте?
template = """ Из следующего текста извлеки информацию: job_title: Как указано в описании вакансии, на том же языке. Проверяй полное совпадение, без учета регистра. Если написан грейд, его нужно убрать (например, Senior Python developer -> Python developer, C++ разработчик (middle, senior) ->C++ разработчик) Если информация явно не определена, поставь значение None company: Как указано в описании вакансии, на том же языке. Проверяй полное совпадение, без учета регистра. Указывай только название (не пиши финтех, крупная компания, мобильная игра и т.д.) Если информация явно не определена, поставь значение None. salary: Числа пиши без пробелов, не пиши тыс. или к.(умножай в таком случае на 1000), не пиши фикс, плюшки, премии, % от продаж, техника и т.д. Не пиши net, gross, на руки и т.д. После числа (диапазона чисел) указывай валюту руб. или $ после пробела. Если указан диапазон, то пиши его через тире, около тире пробелы не ставь (например, 100к-150к рублей -> 100000-150000 руб.). Если указана только нижняя граница (от 2000$ или 100000+руб), то пиши это значение, используя слово от (например, 100к+руб -> от 100000 руб.). Если указана только верхняя граница, то пиши это значение, используя слово до (например, до 100к руб -> до 100000 руб.). Если зарплата указана за час, то в конце добавляй в час. Если информация явно не определена, поставь значение None. tg: Указывай контакт в телеграмм, используя @. Проверяй полное совпадение, с учетом регистра. Если указано несколько контаков, то указывай их через запятую (не забывая про пробел после запятой). Если информация явно не определена, поставь значение None. grade: Возможные значения intern, junior, junior+, middle, middle+, senior, lead. Если указано несколько значений, то пиши их через запятую в порядке возрастания. Если информация явно не определена, поставь значение None. text: {text} {format_instructions} """ job_title_schema = ResponseSchema( name="job_title", description="Как указано в описании вакансии, на том же языке. Проверяй полное совпадение, без учета регистра. " "Если написан грейд, его нужно убрать (например, Senior Python developer -> Python developer, C++ разработчик (middle, senior) ->C++ разработчик)" "Если информация явно не определена, поставь значение None." ) company_schema = ResponseSchema( name="company", description="Как указано в описании вакансии, на том же языке. Проверяй полное совпадение, без учета регистра. " "Указывай только название (не пиши финтех, крупная компания, мобильная игра и т.д.)" "Если информация явно не определена, поставь значение None." ) salary_schema = ResponseSchema( name="salary", description="Числа пиши без пробелов, не пиши тыс. или к.(умножай в таком случае на 1000), не пиши фикс, плюшки, премии, % от продаж, техника и т.д." "Не пиши net, gross, на руки и т.д." "После числа (диапазона чисел) указывай валюту руб. или $ после пробела." "Если указан диапазон, то пиши его через тире, около тире пробелы не ставь (например, 100к-150к рублей -> 100000-150000 руб.)." "Если указана только нижняя граница (от 2000$ или 100000+руб), то пиши это значение, используя слово от (например, 100к+руб -> от 100000 руб.)." "Если указана только верхняя граница, то пиши это значение, используя слово до (например, до 100к руб -> до 100000 руб.)." "Если зарплата указана за час, то в конце добавляй в час." "Если информация явно не определена, поставь значение None." ) tg_schema = ResponseSchema( name="tg", description="Указывай контакт в телеграмм, используя @. Проверяй полное совпадение, с учетом регистра. " "Если указано несколько контаков, то указывай их через запятую (не забывая про пробел после запятой)." "Если информация явно не определена, поставь значение None." ) grade_schema = ResponseSchema( name="grade", description="Возможные значения intern, junior, junior+, middle, middle+, senior, lead. " "Если указано несколько значений, то пиши их через запятую в порядке возрастания." "Если информация явно не определена, поставь значение None." ) response_schemas = [ job_title_schema, company_schema, salary_schema, tg_schema, grade_schema ]@Иван_Александров, так, а где тогда не надо писать, в template или в response schema? Не понимаю, как должны выглядеть тогда строчки, которые я написал?
@Иван_Александров, Я понял, спасибо!